



توضیحات
پروژه شبیه سازی الگوریتم جستجو پراکنده (Scatter Search Algorithm)
الگوریتم جستجو پراکنده
مقدمه
جستجوی پراکنده یک روش تکاملی است که بصورت موفقیت آمیز برای مسائل سخت در مورد بهینه سازی بکار می رود. اصول و مفاهیم اساسی این روش در دهه 1970 بر اساس فرمول هایی پیشنهاد شد که به تاریخ دهه 1960 برای ترکیب قواعد تصمیم گیری و محدودیت های مسئله باز می گشت. جستجوی پراکنده بر خلاف روشهای تکاملی دیگر (مانند الگوریتم های ژنتیک)، بر اساس این قضیه پی ریزی شده است که روش ها و طرح های سیستماتیک برای ایجاد راه حل های جدید، مزایای مهم تری در مقایسه با مزایای توسل به انتخاب تصادفی دارند.
جستجوی پراکنده (SS) ابتدا در مطالعه گلاور (1977) بعنوان کاوشی برای برنامه سازی صحیح معرفی شد. در طرح اولیه، راه حل هایی بصورت عمدی (به بصورت تصادفی) ایجاد شدند تا خصوصیات آنرا در بخش های مختلف فضای راه حل مورد توجه قرار دهد.
طرح جستجوی پراکنده مبنا
1- روش ایجاد تنوع، برای ایجاد مجموعه ای از راه حل های آزمایشی با استفاده از یک راه حل ازمایشی قراردادی (یا راه حل منشأ) بعنوان یک ورودی.
2- روش بهبود، برای تغییر یک راه حل آزمایشی به یک یا چند راه حل آزمایشی پیشرفته (نه راه حل های ورودی و نه راه حل های خروجی نیازمند این نیستند که امکان پذیر و عملی باشند، با اینکه بیشتر توقع می رود که راه حل های خروجی اینگونه باشند. اکر هیچ بهبودی از راه حل آزمایشی ورودی ایجاد نگردد، فرض می شود که راه حل تقویت شده با راه حل ورودی یکسان باشد).
3- بروزرسانی سری منابع، برای ایجاد و حفظ یک سری منابع تشکیل شده از b تعداد از بهترین راه حل های یافته شده (که مقدار b معمولاً کم است و برای مثال از 20 بیشتر نمی شود)، که سازماندهی شده است تا دسترسی مؤثر توسط قسمت های دیگر این روش را فراهم سازد. راه حل ها مطابق با کیفیت یا تنوع خود در سری منابع طبقه بندی می شوند.
4- روش ایجاد زیرمجموعه، برای عملکرد در سری منابع، تا زیرمجموعه ای از راه حل های خود بعنوان مبنایی برای ایجاد راه حل های ترکیبی ایجاد کند.
5- روش ترکیب راه حل، تا یک زیرمجموعه معین از زیرمجموعه های ایجاد شده توسط روش ایجاد زیرمجموعه را به یک یا چند بردار راه حل حل ترکیبی تبدیل کند.
در این انجام پروژه قصد داریم تا یک تابع هزینه ای که یک 10 جمله ای مرتبه اول میباشد را با توجه به دو شرط مطرح شده ماکزیمم کنیم. مساله به صورت پیش فرض به صورت زیر مطرح شده است:

در پروژه انجام شده با متلب، در آغاز، ضرائب چند جملهای به صورت دلخواه توسط کاربر وارد شده و همچنین ضرائب نامعادله را نیز وارد می شود. برای اینکه ضرائب به دلخواه وارد شود کافی است که علامت % را از دو خط برنامه که در زیر آمده است بردارید و آن دو جمله ای که OF و C را به صورت دستی وارد نموده ایم را حذف کنید.
در برنامه ارائه شده، در آغاز، ضرائب چند جملهای به صورت دلخواه توسط کاربر وارد شده و همچنین ضرائب نامعادله را نیز وارد می شود.
در قسمت Generate Population می خواهیم جمعیت اولیه را ایجاد نماییم. ابتدا مرجع را به صورت یک بردار صفر در نظر می گیریم. X=zeros(1,10) سپس با توجه به دو فرمول زیر جمعیتی به اندازه 10 را ایجاد می کنیم:
x’1+hk=1-x1+hk for k=0,1,…,n/h
x”i=1-x’I
که در این فرمول H مقداری کمتر از n-1 یعنی کمتر از 9 می باشد که ما 5 فرض کرده ایم.
کل جمعیت را که به عنوان راه حل می باشد در Y ذخیره نموده ایم.
در قسمت Improvement Method نیز ابتدا مقدار ارزش و مقادیر وزنی که در معادله و نامعادله ایجاد شده است به دست می آوریم. نسبت ضرائب هر یک از ورودی ها را با توجه به تقسیم ضرائب معادله به نامعادله به دست میآوریم.
ااگر وزن نامعادله بیشتر از 100 شد ابتدا درآیه مربوط به کوچک ترین نسبت را صفر می کنیم و دوباره وزن جدید را به دست می آوریم و درصورتی که باز هم بزرگتر از 100 بود دومین کوچک ترین نسبت را نیز صفر می کنیم و همینطور ادامه می دهیم تا وزن به کمتر از 100 برسد. حال قسمت بعدی شروع می شود و بزرگ ترین نسبت را یک می کنیم و دوباره وزن را چک می کنیم اگر برگتر از 100 شده بود که آن را صفر می کنیم اگر کمتر بود دومین بزرگترین نسبت را یک می کنیم و به همین روال ادامه می دهیم.
در قسمت Reference Set Update ابتدا جمعیت اول را چک می کنیم و آنهایی که تکراری هستند فقط یکی از آن ها را نگه می داریم و بقیه رو صفر می کنیم. بعد با توجه به مقدار تابع هزینه آن ها را مرتب می کنیم، و 8 تا را به عنوان حل های به روز شده در نظر می گریم. سه تای بزرگ تر را به عنوان حل های اصلی و 5 تا بعدی را نیز بر می داریم.
در قسمت clculate Distance فاصله هریک از 5 حل انتخابی را از 3 تا بهترین حل ها به صورت زیر به دست می آوریم.
(0, 1, 1, 1, 0, 0, 0, 0, 1, 1) Solution 1
(0 ,1 ,1 ,1 ,1 ,0 ,0 ,0 ,1 ,0) Solution 8
(0+0+0+0+1+0+0+0+0+1) = 2
پس از اینکه فاصله ها را به دست آوردیم دو مورد از حل ها که بیشترین فاصله را داشتند انتخاب می کنیم و سه تا هم که حل های بهترین را داشتیم پس می شود 5 حل.
در قسمت Subset Generation حالت هایی از زیر مجموعه های 2،3،4 و 5 تایی از 5 حل فوق را به صورتی که در زیر آمده است به دست می آوریم.
T1S=[1,2;1,3;1,4;1,5;2,3;2,4;2,5;3,4;3,5;4,5]; % Type 1 Solutions
T2S=[1,2,3;1,4,3;1,5,3;2,4,3;2,5,3;4,5,3]; % Type 2 Solutions
T3S=[1,2,3,4;1,5,3,2;4,5,3,1]; % Type 3 Solutions
T4S=[1,2,3,4,5]; % Type 4 Solutions
که در آن حل نوع اول یعنی از ترکیب دو حل ایجاد بشود و به همین صورت تا حل نوع 4 که ترکیب هر 5 حل انتخابی می باشد.
در حالت کلی 20 حل مختلف به دست آمد که حالا باید آنها را باهم به صورتی که در انواع چهارگانه حل آمده است با هم ترکیب کنیم.
برای ترکیب از فرمول زیر استفاده می کنیم:
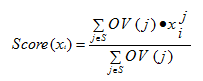
که می شود به زبان ساده تر ارزش هر حل تقسیم بر جمع ارزش حل هایی که با آن ترکیب شده است ضرب در خود حل.
(1,2)àV(1)/(V(1)+V(2)).*X1 & V(2)/(V(1)+V(2)).*X2
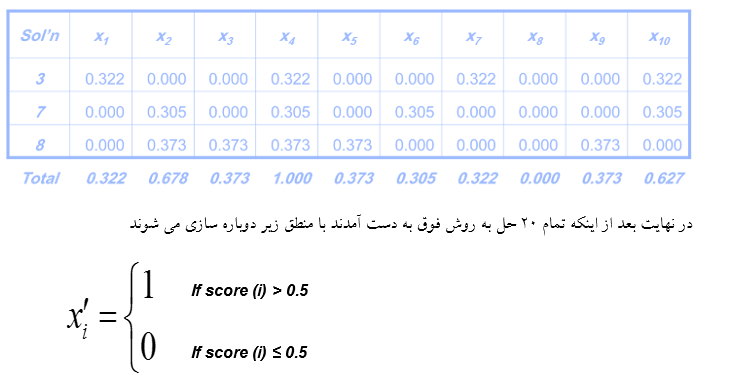
بعد در نهایت این دو را با هم جمع می کنیم تا ترکیبشان یک حل به دهد مانند جدول زیر:

که درنتیجه جدول فوق به صورت زیر می شود:
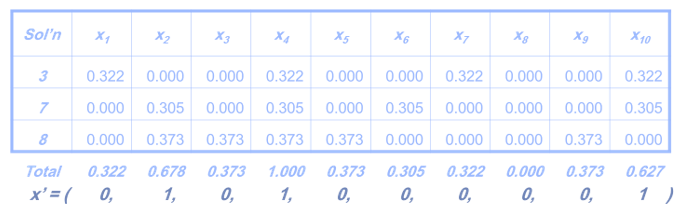
حال که حل ها به صورت کامل به دست آمدند با چک کردن مقدار تابع هزینه به ازای حل های مختلف بیشترین مقدار به عنوان جواب مساله بهینه سازی خواهد بود.
نکات قابل ذکر:
- پروژه شبیه سازی الگوریتم جستجو پراکنده با متلب توسط کارشناسان گروه ۱.۲.۳ پروژه پیاده سازی گردیده و به تعداد محدودی قابل فروش می باشد.
- فایل های پروژه به صورت کامل به همراه فایل راهنما پس از خرید فایل در اختیار شما قرار خواهد گرفت.








نقد و بررسیها
هنوز بررسیای ثبت نشده است.