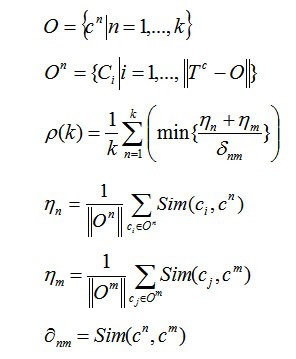
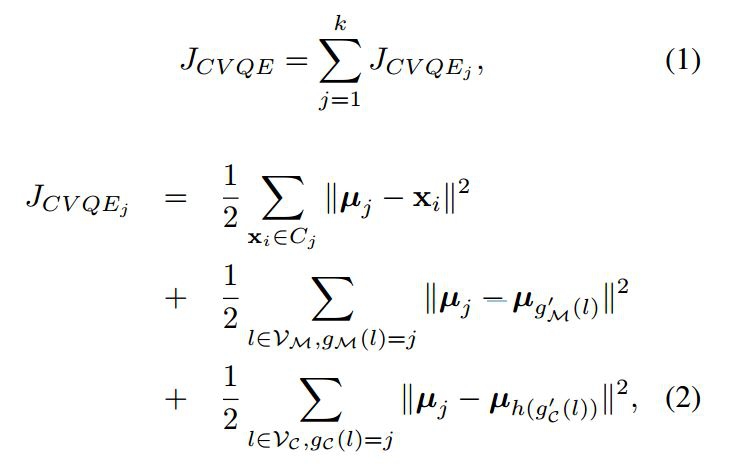
توضیحات
شبیه سازی تابع جریمه و دقت برای الگوریتم cop k means با متلب
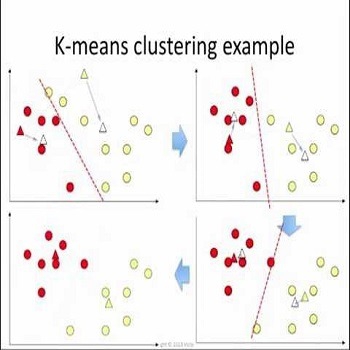
روش کامینز K-Means یکی از روش های خوشه بندی داده ها در داده کاوی است. این روش علیرغم سادگی آن یک روش پایه برای بسیاری از روشهای خوشهبندی دیگر (مانند خوشهبندی فازی) محسوب میشود. این روش روشی انحصاری و مسطح محسوب میشود. برای این الگوریتم شکلهای مختلفی بیان شده است. ولی همه آنها دارای روالی تکراری هستند که برای تعدادی ثابت از خوشهها سعی در تخمین موارد زیر دارند:
بدست آوردن نقاطی به عنوان مراکز خوشهها این نقاط در واقع همان میانگین نقاط متعلق به هر خوشه هستند. نسبت دادن هر نمونه داده به یک خوشه که آن داده کمترین فاصله تا مرکز آن خوشه را دارا باشد. در نوع سادهای از این روش ابتدا به تعداد خوشههای مورد نیاز نقاطی به صورت تصادفی انتخاب میشود. سپس در دادهها با توجه با میزان نزدیکی (شباهت) به یکی از این خوشهها نسبت داده میشوند و بدین ترتیب خوشههای جدیدی حاصل میشود. با تکرار همین روال میتوان در هر تکرار با میانگینگیری از دادهها مراکز جدیدی برای آنها محاسبه کرد و مجدادأ دادهها را به خوشههای جدید نسبت داد. این روند تا زمانی ادامه پیدا میکند که دیگر تغییری در دادهها حاصل نشود. تابع زیر به عنوان تابع هدف مطرح است.
در الگوریتم Kmeans ابتدا k عضو (که k تعداد خوشهها است) بصورت تصادفی از میان n عضو به عنوان مراکز خوشهها انتخاب میشود. سپس n-k عضو باقیمانده به نزدیکترین خوشه تخصیص مییابند. بعد از تخصیص همه اعضا مراکز خوشه مجدداً محاسبه میشوند و با توجه به مراکز جدید به خوشهها تخصیص مییابند و این کار تا زمانی که مراکز خوشهها ثابت بماند ادامه مییابد.
تعیین تعداد خوشهها
بهترین خوشهبندی آن است که مجموع تشابه بین مرکز خوشه و همه اعضای خوشه را حداکثر و مجموع تشابه بین مراکز خوشهها را حداقل کند. برای انتخاب بهترین خوشه ابتدا براساس نظرات خبره و مطالعات قبلی یک محدوده پیشنهادی برای تعداد خوشهها مشخص میشود. معمولاَ این محدوده بین انتخاب میشود. سپس مقدار ρ(k) برای هریک از مقادیر k محاسبه میشود. مقداری از k که در آن ρ(k) حداکثر شود، به عنوان تعداد بهینه خوشهها انتخاب میشود. به این ترتیب میتوان تعداد خوشهای را انتخاب نمود که به ازای آن فاصله بین مراکز خوشهها و شباهت مراکز خوشه با اعضای درون هر خوشه حداکثر است. کیفیت نتایج خوشهبندی با K خوشه بصورت زیر تعریف میشود:
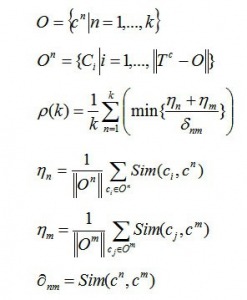
در این معادله O مجموعه مراکز خوشه ها، Cn مراکز خوشهها، On مجموعه عناصری که به عنوان مراکز خوشه انتخاب نشدهاند، Tc مجموعه کلیه عناصری باشد که خوشهبندی روی آنها صورت گرفته باشد، nη میانگین شباهت بین مرکز خوشه Cn و همه عناصر خوشه On است، mη میانگین شباهت بین مرکز خوشه Cm و همه عناصر خوشه Om است، در نهایت nmδ بعنوان شباهت Cn و On تعریف میشود.
شبیه سازی تابع جریمه و دقت برای الگوریتم cop k means با متلب توسط کارشناسان گروه ۱.۲.۳ پروژه پیاده سازی گردیده و به تعداد محدودی قابل فروش می باشد.فایلهای پروژه به صورت کامل پس از خرید فایل بلافاصله در اختیار شما قرار خواهد گرفت.
سفارش پروژه مشابه
درصورتیکه این پروژه دقیقا مطابق خواسته شما نمی باشد، با کلیک بر روی کلید زیر پروژه دلخواه خود را سفارش دهید.






نقد و بررسیها
هنوز بررسیای ثبت نشده است.