
توضیحات
مقدمه:
خوشه بندی اجماعی چندین پارتیشن از داده را با یکدیگر ترکیب کرده و یک پارتیشن که از لحاظ پایداری و کیفیت بهتر و همچنین مقاوم تر خواهد بود را تولید میکند. کیفیت یک پارتیشن با استفاده از معیارهای داخلی و خارجی قابل محاسبه است. اگر برچسب داده ها در دست باشد از معیارهای خارجی و در غیر اینصورت از معیار داخلی میتوان استفاده کرد. معیارهای داخلی مانند جمع مربعات خطا(SSE) ایندکس Calinski Harabasz (CHI) و … میباشند. همچنین برای معیارهای خارجی میتوان به NMI ARI, F-M,اشاره کرد. معیارهای داخلی توابعی هستند که پارتیشن و دادههای اصلی را به عنوان ورودی گرفته و یک مقدار به عنوان ارزش برای پارتیشن در خروجی ایجاد میکنند. در مقابل معیارهای خارجی پارتیشن و تنها برچسب ورودی ها را گرفته و ارزشی برای پارتیشن در خروجی ایجاد میکنند . هر دومعیارها بطورگسترده ایی در پژوهش ها مورد استفاده قرار میگیرند. در این مقاله از معیارهای خارجی برای محاسبه عملکرد الگوریتم پیشنهادی برای تولید پارتیشن استفاده میکنیم.
در خوشه بندی اجماعی دو راهکار کلی برای تولید مجموعهایی از پارتیشن ها(ensemble) وجود دارد . در راهکار اول با استفاده از الگوریتم های خوشه بندی ناهمگن (غیریکسان) و راهکار دوم با استفاده از خوشه بندی همگن (یکسان) مجموعه ensemble را تولید میکنند. در راهکار اول هر پارتیشن با استفاده از یک الگوریتم خوشه بندی مجزا و متفاوت تولید میشود در حالی که در راهکار دوم همهی پارتیشن ها با استفاده از یک الگوریتم خوشه بندی یکسان تولید میگردند.
تابع اجماع هم میتواند بر مجموعه ایی از دندروگرام ها و هم مجموعه ایی از پارتیشن ها اعمال شوند. در روش اعمال بر پارتیشن ها حالتهای متفاوتی وجود دارد که در این مقاله از ماتریس co-association استفاده شده است. در این روش ابتدا مجموعه پارتیشن ها به یک ماتریس شباهت تبدیل میشود. که عنصر آن نشان دهنده تعداد دفعاتی است که دادهی و به طور همزمان در یک خوشه باشند.سپس با استفاده از یک الگوریتم خوشه بندی مانند الگوریتم های خوشه بندی سلسله مرتبه ایی پارتیشن نهایی بدست میآید.
دو عامل مهم در مساله تولید ensemble ،کیفیت خوشه و واگرایی بین مجموعه ها است. فاکتور اول به این معنی است که کیفیت خوشه ها در مجموعه مهم است و باید در مساله تولید ensemble در نظرگرفته شود. سه راه کار برای این موضوع وجود دارد که در این مقاله یکی از آن ها مورد بحث است. در این روش یک تابع اجماع با توجه به وزنی که به خوشه اختصاص داده میشودکه مرتبط با کیفیت خوشه است پارتیشن نهایی را تولید میکند. فاکتور دوم نیز به این معنی است که خوشه های ensemble باید تا حد امکان واگرا باشد. دو روش برای این موضوع وجود دارد : تولید یک ensemble با مقدار بالای واگرایی بین پارتیشن ها و تولید یک ensemble بدون توجه به واگرایی و سپس انتخاب زیر مجموعه ایی از آن ها که تا حد امکان واگرا باشند. در بعضی از پژوهش ها مساله واگرایی مورد بحث قرار گرفته هرچند کیفیت خوشه ها مورد توجه نبوده است.
به منظور توجه به کیفیت خوشه ها ماتریس co-association را وزن دار میکنیم. به این منظور و در فرایند وزن دار کردن این ماتریس یک وزن به خوشه متناسب با ارزش آن خوشه اختصاص داده میشود. ارزش یک خوشه با توجه به وابستگی خوشه بدست میآید که در زیر فرآیند بدست آوردن آن توضیح داده میشود:
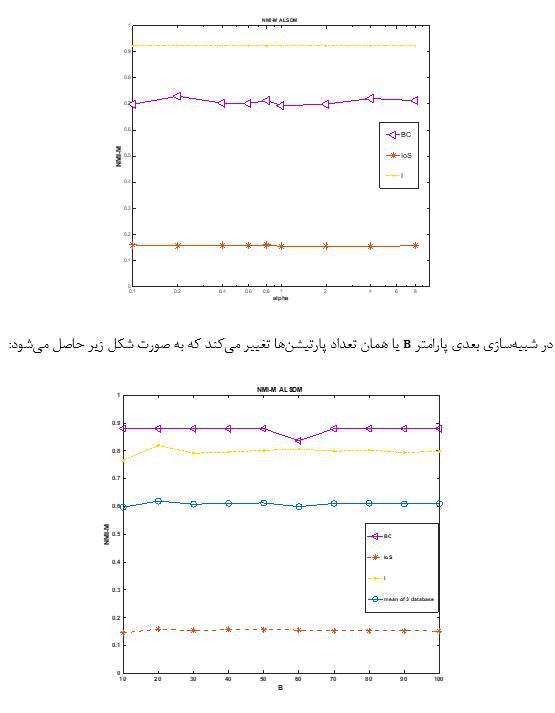
بعد از بدست آوردن ماتریسهای بالا نوبت به استفاده از یک تابع اجماع میرسد که در این مقاله از روش خوشهبندی سلسله مراتبی پیوند میانگین استفاده شده است. با در نظر گرفتن تعداد خوشه های مطلوب در پارتیشن نهایی برابر با ۳ نتیجه برای هر دو ماتریس به صورت زیر حاصل میشود که باز هم برابر با مقادیر گزارش شده در مقاله است.
|
3 |
1 |
3 |
3 |
1 |
1 |
3 |
2 |
2 |
3 |
2 |
2 |
2 |
3 |
3 |
1 |
|
|
2 |
1 |
2 |
2 |
1 |
1 |
2 |
3 |
3 |
2 |
3 |
3 |
3 |
2 |
2 |
1 |
تمام نتایج بدست آمده در بالا صحت پیادهسازی الگوریتم داده شده در مقاله را تایید میکنند.
در مثال قبلی خوشه ها را به صورت فرضی در نظر گرفتیم.برای بدست آوردن خوشهها و پارتیشن های مختلف باید از یک روش خوشه بندی با تعداد خوشه های مختلف استفاده نمود تا یک پارتیشن بدست بیاید. مسلما تعداد پارتیشنها و تعداد خوشههای هر یک در عملکرد الگوریتم تاثیر گذار است. همچنین تاثیر پارامترهای خود الگوریتم مانند نیز باید بررسی گردد. شکل ۲ مقاله شبه کد استفاده شده برای تولید پارتیشن ها و محاسبه ماتریسهای CA وزندار و همچنین تولید پارتیشن نهایی أورده شده است. پارامترهایی که در این الگوریتم استفاده شده اند به صورت زیر هستند:
|
تعداد خوشه های مورد نظر در پارتیشن نهایی |
C |
|
الگوریتم خوشه بندی پایه برای تولید خوشهها و پارتیشنها |
bca |
|
تعداد پارتیشنها |
B |
|
دیتابیس |
D |
|
خوشهبندی بر اساس برچسبهای واقعی نمونهها در دیتابیس |
|
|
پارامتر محاسبه FDM |
به منظور تولید پارتیشن های مختلف یک الگوریتم خوشهبندی را در نظر گرفته و هر بار با تغییر تعداد خوشهها و یا مقدار اولیه مراکز خوشه ها پارتیشن های مختلف را بدست میآوریم. الگوریتم خوشهبندی استفاده شده جهت تولید پارتیشنها در مقاله k-means میباشد. مقاله توصیه کرده است که برای مقدار اولیه مراکز خوشهها از روش KA در مرجع ۴۴ مقاله استفاده کنیم. این روش همواره برای k ثابت، مراکز خوشههای یکسانی میدهد. هرچند برای تولید پارتیشنهای کافی هم از این روش و هم از روش تولید تصادفی مراکز خوشه استفاده شده است.
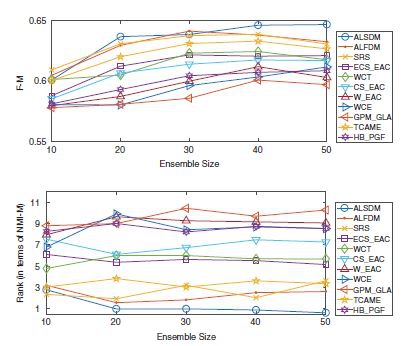
پس از مشاهده موفقیت گروه در یادگیری تحت نظارت (مانند طبقه بندی)، آن را به یادگیری بدون نظارت گسترش دادند. بنابراین، گروه خوشهای، که چندین پارتیشن یا خوشههای داده پایه (که به عنوان مجموعه گروه نامیده میشوند) را در یک راهحل خوشهبندی معمولاً بهتر که معمولاً به عنوان پارتیشن توافقی نامیده میشود، ادغام میکند. هر روش گروه خوشه ای سعی می کند یک معیار خاص را در طول استخراج پارتیشن اجماع از مجموعه گروه بهینه کند. اما گروههای خوشهای سنتی همه اعضای استخر را در ایجاد پارتیشن اجماع دارای اهمیت یکسانی در نظر میگیرند. به این معنا که هر پارتیشن یا خوشه پایه به طور معادل در الگوریتم گروه خوشه شرکت می کند. در واقع، آنها از در نظر گرفتن هر یک از اعضای گروه با توجه به اهمیت آن غافل می شوند. اما بدیهی است که برخی از خوشه های با کیفیت بیشتر مستحق تاکید بیشتر و برخی از خوشه های با کیفیت کمتر در حین ایجاد پارتیشن اجماع مستحق تاکید کمتری هستند. این مقاله (الف) معیاری برای ارزیابی کیفیت هر خوشه دلخواه، (ب) مکانیزمی برای پیشبینی کیفیت محاسبهشده یک خوشه به یک مقدار وزن معنادار، و (ج) رویکردی برای اعمال مقادیر وزنی پیشنهاد میکند. خوشه های اساسی در فرآیند مجموعه خوشه. نتایج تجربی انجام شده بر روی تعدادی از مجموعه دادههای استاندارد دنیای واقعی نشان میدهد که روش پیشنهادی بهتر از روشهای هنر عمل میکند.
کلیدواژه ها قابلیت اطمینان خوشه، مجموعه خوشه بندی، پارتیشن اجماع، آنتروپی
- فایلهای پروژه به صورت کامل پس از خرید فایل بلافاصله در اختیار شما قرار خواهد گرفت.








نقد و بررسیها
هنوز بررسیای ثبت نشده است.