




توضیحات
پیاده کردن الگوریتم خوشه بندی k-means با نرم افزار Rapid Miner
توضیح مسئله
در این تمرین قصد داریم تا روی یک دیتاست عملیات خوشه بندی Kmeans را انجام دهیم. برای این کار دیتاست سرطان سینه در سایت UCI استفاده خواهیم کرد. این الگوریتم را به ازای تعداد خوشه مختلف و با استفاده از معیار davies bouldin ارزیابی خواهیم کرد تا بهترین تعداد خوشه را محاسبه کنیم.
تفسیر داده ها
همانگونه که ذکر شد از داده های سایت UCI برای این تمرین استفاده کرده ایم. دیتاست انتخابی ما دیتاست سرطان سینه است که در لینک زیر قابل دسترس است
https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Diagnostic)
مشخصات کلی این دیتاست در شکل زیر آورده شده است
|
تعداد ویژگی ها |
تعداد کلاس |
تعداد نمونه |
سال جمع آوری |
مقادیر ویژگی ها |
|
10 |
3 |
569 |
1995 |
Real |
این دیتاست شامل 569 نمونه است و دارای 32 ویژگی است. اما در بیشتر تحقیقات تنها از 10 ویژگی استفاده میکنند به همین دلیل در این تمرین نیز از دیتاستی که تنها شامل 10 ویژگی هست استفاده کرده ایم. مقادیر ویژگی ها به صورت real است. این دیتا در سال 1995 جمع آوری شده است.
الگوریتم خوشه بندی Kmeans
در این الگورتیم در ابتدا تعدادی نقطه به صورت تصادفی به عنوان مرکز خوشه انتخاب میشوند.
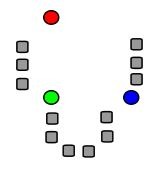
سپس سایر نقاط را با توجه به این نقاط و بر حسب فاصله خوشه بندی میکنیم
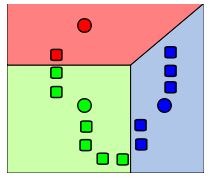
سپس از کلیه نقاط در هر خوشه میانگین گیری میکنیم و میانگین خوشه را معادل این میانگین قرار میدهیم. در نتیجه مراکز خوشه ها تغییر خواهند کرد. مانند شکل زیر
و دوباره خوشه بندی با توجه به مراکز خوشه جدید اعمال میشود. خوشه های جدید پیدا میشوند. دوباره از نقاط میانگین گیری میشود. مراکز خوشه جدید پیدا میشوند و دوباره بر حسب مراکز خوشه جدید عملیات بالا را تکرار میکنیم. این عملیات آنقدر تکرار میشود که مراکز خوشه در دورهای متعدد بعدی، تغییر چندانی نداشته باشند.
مراحل پردازشی
برای انجام این تمرین باید مراحل پردازشی زیر طی شود تا بتوانیم به جواب نهایی برسیم
- حذف ویژگی برچسب از داده ها زیرا در خوشه بندی نیازی به برچسب نداریم
- کنترل مقادیر گمشده (Missing Value) در صورت وجود
- خوشه بندی داده
- ارزیابی خوشه بندی به ازای مقادیر مختلف k با استفاده از معیار davies bouldin
برای هر کدام از مراحل بالا، یک جعبه پروسس انتخاب میشود که به شرح زیر هستند.
- باکس Select Attributes
- باکس Replace Missing Value
- باکس Kmeans Clustering
- باکس Cluster Distance Performance
شکل کلی پروسه های انجام شده به صورت زیر خواهد بود
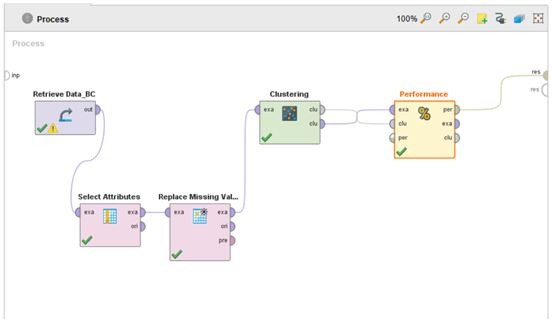
پیاده کردن الگوریتم خوشه بندی k-means با نرم افزار Rapid Miner توسط کارشناسان گروه ۱.۲.۳ پروژه پیاده سازی گردیده و به تعداد محدودی قابل فروش می باشد.
- فایلهای پروژه به صورت کامل پس از خرید فایل بلافاصله در اختیار شما قرار خواهد گرفت.








دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.