




توضیحات
پروژه تعبیه جملات و کلمات (embedding) قرآن کریم به روشهای lda2vec ، EMLO ،p-mean و نمایش در تنسوربورد با پایتون
برنامهها را در محیط jupyter notebook پیاده شده است. برای اجرای برنامهها باید کتابخانههای numpy، pandas ، gensim، matplotlib و tensorflow و tensorboard را بر روی پایتون خود نصب داشته باشید. برای نصب نوتبوک و یا بستههای جدید میتوانید دستورات زیر را در پنجره خط فرمان ویندوز (Command Prompt) اجرا کنید:
pip install jupyter
pip install tenorflow
pip install gensim
برای دیدن لیست کامل کتابخانههای نصب شده در پایتون و شماره نسخههای آنها میتوانید دستور pip freeze را در پنجره خط فرمان ویندوز اجرا کنید
همچنین برنامهها را میتوانید در محیط گوگلکلاب (google colaboratory) نیز اجرا کنید. دستور ات سلولهای 2 تا 5 در ابتدای برنامهها فقط برای اجرا در محیط گوگلکلاب میباشند و در حالت عادی برای اجرا در نوتبوک غیرفعال است. این دستورات برای آمادهسازی محیط گوگلکلاب میباشند. توضیحات کامل روش اجرای برنامهها در محیط گوگلکلاب را در آخر گزارش نوشتم. گوگلکلاب یک gpu قدرتمند Tesla k8 شرکت NVIDIA را در اختیار کاربر قرار میدهد که سرعت اجرا و آموزش مدلهای شبکهای عصبی عمیق را افزایش میدهد. همچنین اگر در نصب ماژول tensorflow در پایتون مشکل داشتید و در هنگام import کردن این ماژول در نوتبوک پیغام خطا میدهد، میتوانید برنامهها را روی گوگلکلاب اجرا کنید. در گوگلکلاب بسیاری از ماژول از پیش نصب میباشد و نیازی به نصب آنها ندارید. انجام پروژه پایتون
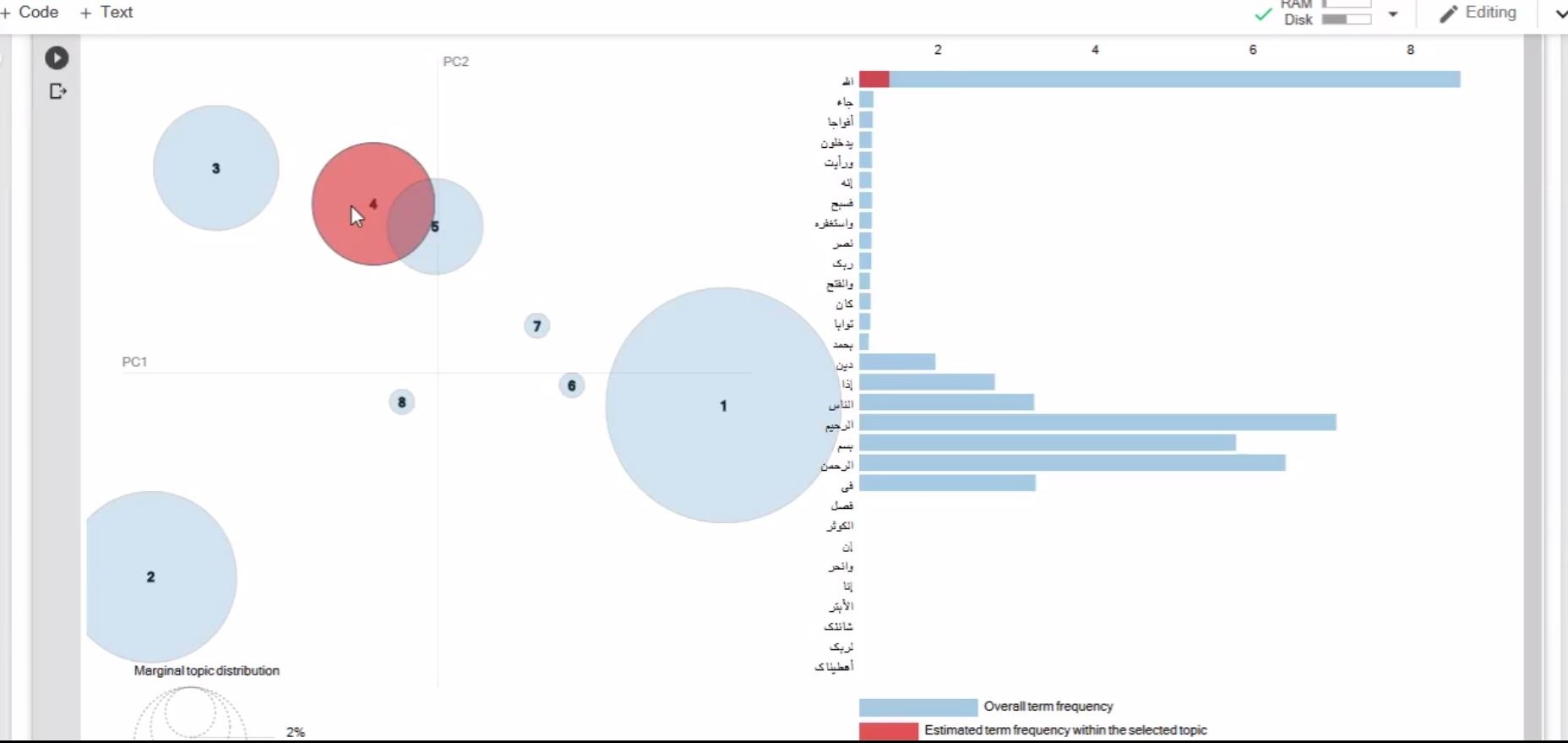
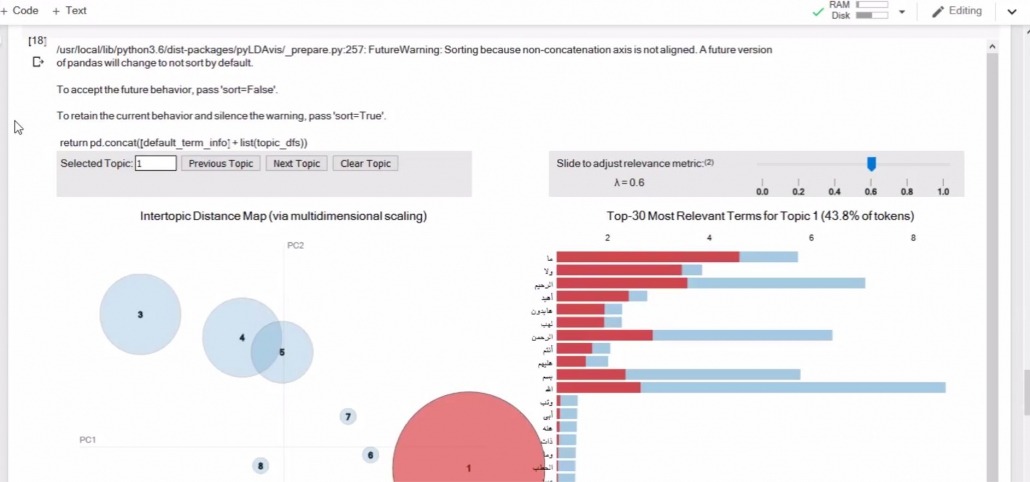
توضیحات خطهای برنامه Main1 :
خواندن متن آیهها از فایل داده:
فایل quran.csv با فرمت comma-seperated values (csv) میباشد. این فایل دارای سه ستون با نامهای num_sura (شماره سوره)، num_verse (شماره آیه) و verse (متن آیه) میباشد که با علامت | از یکدیگر جدا میشوند. این فایل را میتوانید با برنامه Notepad ویندوز نیز باز کنید و بخوانید.
پیش پردازش متن آیه ها:
متد (تابع) sub از ماژول re برای جایگزین کردن یک کاراکتر با کاراکتر دیگر در متن استفاده میشود. برای مثال برای جایگزین کردن کاراکتر x با y در رشته text از دستور text=re.sub(“[x]”, “y”, text) استفاده میکنیم. همچنین میتوانیم مجموعه ای از کاراکترها را با یک کاراکتر جایگزین کنیم.
جداسازی متن آیهها (tokenization) :
ابتدا با متد str متن آیههای df[“verse”] را به رشتهها (string) و سپس با تابع split() متن هر رشته (آیه) را به توکنها (کلمه ها) جداسازی میکنیم:
الگوریتم تعبیه word2vec :
الگوریتم word2vec از دو ساختار skip-gram و cbow (continuous bag of words) برای تولید بردارهای تعبیه کلمهها استفاده میکند. در هردو مدل skip-gram و cbow فرض میکنیم یک پنجره متحرک با طول ثابت داریم و آن را روی یک جمله حرکت میدهیم. کلمه ای که در وسط قرار میگیرد، کلمه هدف و کلمههایی که در سمت چپ و راست در داخل این پنجره متحرک(لغزان) قرار میگیرند کلمههای محتوا میباشند. مدل skip-gram به شرط داشتن کلمه هدف، احتمال وقوع کلمههای محتوایی (کلمههای همسایگی) را پیشبینی میکند. اما در مقابل مدل cbow (continuous bag of words) کلمه هدفرا از روی کلمههای محتوایی پیشبینی میکند. به عبارت دیگر احتمال وقوع کلمه هدف را به شرط داشتن کلمههای محتوایی قبل و بعد از آن پیشبینی میکند:
تولید بردارهای تعبیه کلمهها برای تنسور بورد:
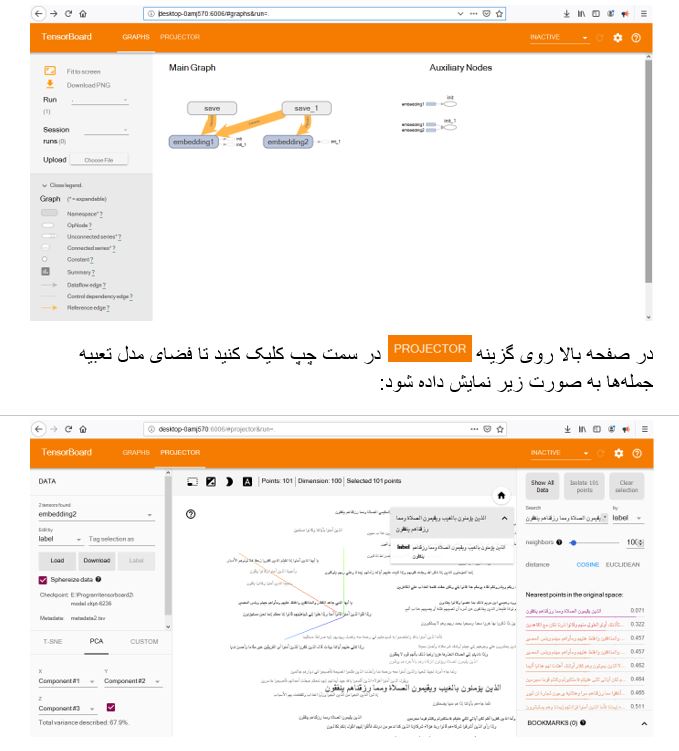
Tensorboard دارای یک بصریساز (visualizer) به نام embedding projector میباشد که این امکان را میدهد تا دادههای با ابعاد بالا را بهصورت تعاملی (interactively) نمایش دهیم و تحلیل نماییم. پس از آموزش مدل word2vec، بردارهای تعبیه کلمهها به صورت یک ماتریس با ابعاد V سطر و N ستون (VxN) میباشد. V تعداد کلمههای فرهنگ لغت در مدل و N طول بردار تعبیه هر کلمه میباشد. ابتدا باید ماتریس تعبیه کلمهها (w2v) را ایجاد کنیم. با دستور np.zeros( , ) از کتابخانه (numpy) npیک ماتریس با تعداد سطرهای vocab_size و تعداد ستونهای model.layer1_size و با مقادیر اولیه صفر تولید میکنیم. ابعاد لایه اول یعنی model.layer1_size برابر طول بردار تعبیه کلمهها میباشد. در مرحله بعد این ماتریس را با مقادیر بردارهای تعبیه کلمهها پر میکنیم:
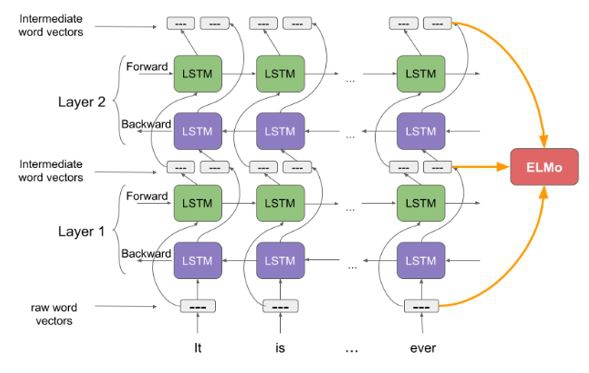
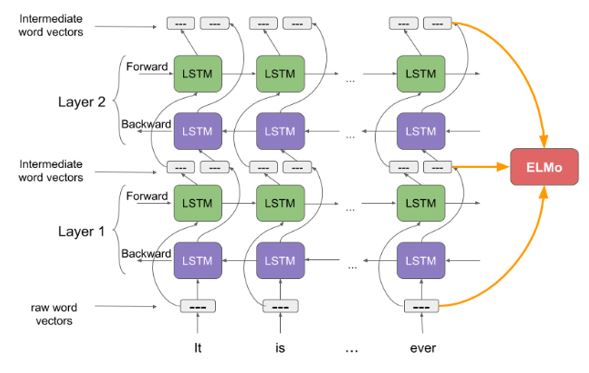
معرفی الگوریتم تعبیه ELMO (Embeddings from Language Model) :
برخلاف الگوریتمهای تعبیه مانند word2vec و glove که همواره برای هر کلمه در متن یک بردار تعبیه ثابت میدهند، الگوریتم elmo به هر کلمه یا توکن با توجه به موضوع و زمینه (context) متن یک بردار تعبیه میدهد. به عبارت دیگر بردار تعبیه elmo تابعی از کل جمله ای است که آن کلمه در آن قرار دارد. بنابراین یک کلمه میتواند در جملههای مختلف بردارهای تعبیه متفاوت داشته باشد. elmo همان گونه که از نام آن نیز مشخص است مانند یک مدل زبانی (Language Model) عمل میکند. در یک مدل زباني هدف اين است که برای هر جمله يا دنباله از کلمهها، يک مدل احتمالاتی ایجاد کنیم و بر مبنای آن، کلمه بعدی در جمله را بر اساس کلمههای قبلی پیشبینی کنیم.
الگوریتم تعبیه elmo از شبکههای عصبی عمیق (Long Short-Term Memory) LSTM استفاده میکند. مطابق شکل زیر الگوریتم elmo از دو لایه شبکه bi-directional LSTM (دو طرفه) که بر روی یکدیگر الحاق (concatenate) میشوند، استفاده میکند. به دلیل استفاده از حالت دو طرفه، الگوریتم elmo میتواند هم الگوی کلمههای بعدی و هم الگوی کلمهها قبلی را به صورت هم زمان در نظر بگیرد.بردار تعبیه elmo از ترکیب خروجیهای دو لایه شبکههای bi-lstm تولید میشود. هر لایه دارای دو پیمایش (pass) میباشد: پیمایش رو به جلو (forward pass) و پیمایش رو به عقب (backward pass). پیمایش رو به جلو دارای اطلاعات کلمه فعلی و اطلاعات زمینه (context) قبل از آن کلمه میباشد. پیمایش رو به عقب دارای اطلاعات کلمه فعلی و اطلاعات زمینه بعد از آن کلمه میباشد. ترکیب این دو پیمایش، بردار میانی کلمه (intermediate word vector) را تشکیل میدهند. بردارهای میانی کلمهها به لایه بعدی شبکههای عصبی bi-lstm وارد میشوند. بردار تعبیه نهایی برابر مجموع وزن دار بردارهای خام کلمهها و و بردارهای میانی کلمهها میباشد. انجام پروژه برنامه نویسی
پیادهسازی الگوریتم elmo :
برای تولید برداهای تعبیه کلمههای elmo از پیادهسازی اصلی این الگوریتم در سایت گیتهاب آن با آدرس زیر استفاده میکنیم:
https://github.com/allenai/bilm-tf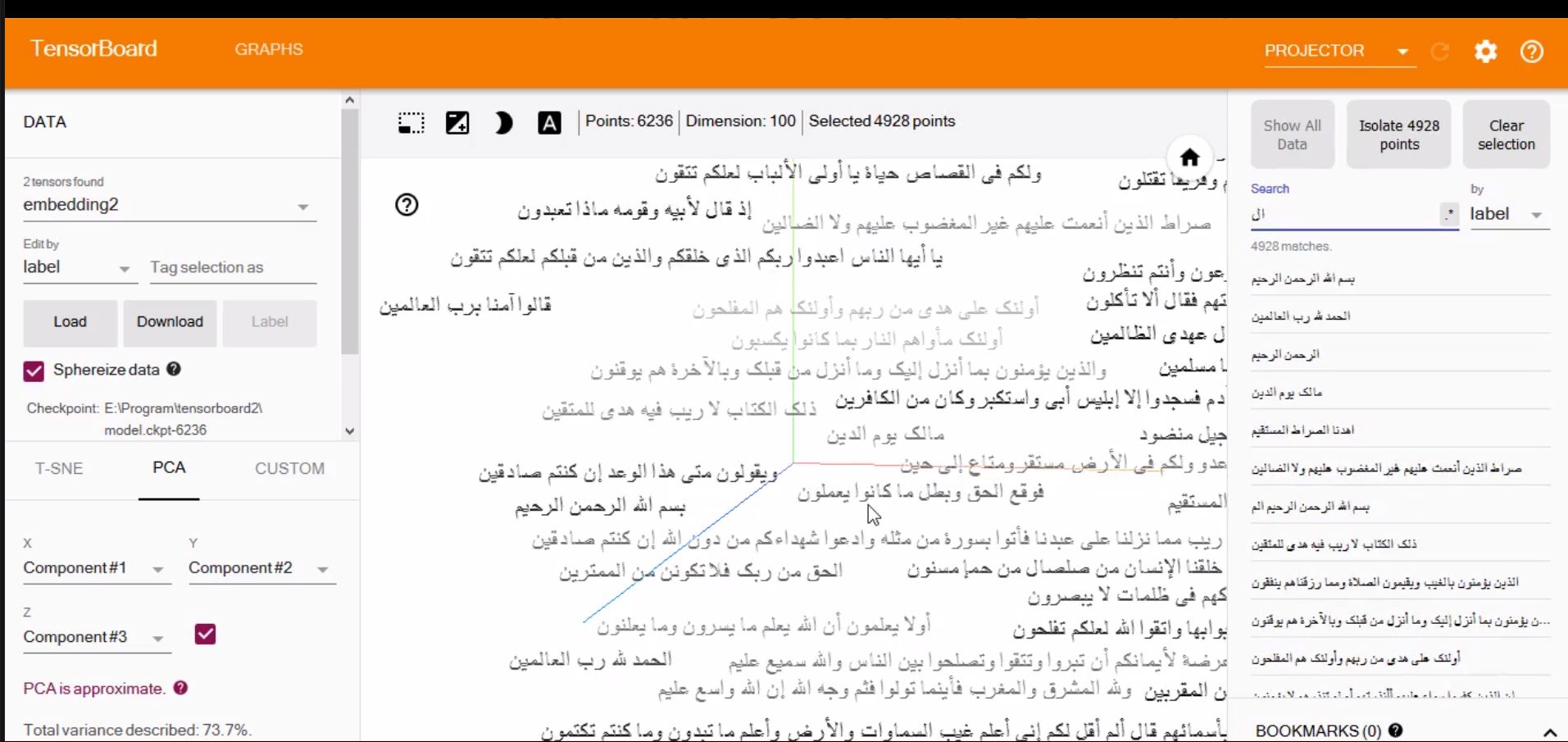
برنامه نویسی خطایاب املایی به زبان پایتون python توسط کارشناسان گروه ۱.۲.۳ پروژه پیاده سازی گردیده و به تعداد محدودی قابل فروش می باشد.فایلهای پروژه به صورت کامل پس از خرید فایل بلافاصله در اختیار شما قرار خواهد گرفت.
سفارش پروژه مشابه
درصورتیکه این پروژه دقیقا مطابق خواسته شما نمی باشد، با کلیک بر روی کلید زیر پروژه دلخواه خود را سفارش دهید.









دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.