توضیحات
عنوان: راهکار مدیریت کش GPGPU مقاوم در برابر سربار مفرط تعویض با اجتناب از ناسازگاری آگاه از جریان
- چکیده
- مقدمه
- مدل برنامهنویسی GPGPU و معماری پایه
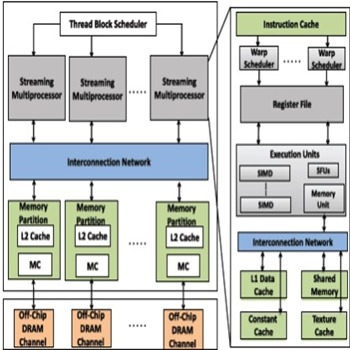
- معماری پایه
- مدل برنامهنویسی GPGPU
- محیط شبیهسازی
- طرح مدیریت کش SACAT
- کنترل دریچه نخ پویا با استفاده از نمونه برداری هستهای
- مکانیزم DWT-CS
- مقایسه با SWT و CCWS
- سربار پیاده سازی
- کش جایگذاری بیتی تصادفی کاذب
- سربار پیاده سازی
- مقایسه با استفاده از گذرگاه فرعی کش
- مقایسه با کشهایی با وابستگی زیاد
- گذردهی کش fine-grained پویا (FG-CB)
- مکانیزم گذر دهیکش fine-grained
- سربار پیاده سازی
- آدرس پایه در مقایسه با کش Per-PC
- قرار دادن همه موارد روی هم (SACAT)
- نتیجه گیری و کارهای آتی
- منابع
چکیده
واحدهای پردازش گرافیکی مدرن (GPUs)، مجهز به کشهای L1 و L2 همهمنظورهای جهت کاهش تقاضای پهنای باند حافظه و بهبود کارایی برخی از برنامههای کاربردی GPU همهمنظوره نامنظم (GPGPU) هستند. بااینحال، به دلیل وجود نخ بندی[1] چندگانه عظیم، کشهای GPGPU از ارتباطات منابع سِروِر و به اشتراکگذاری کمِ دادهها، رنج میبرند که این مسئله منجر به کاهش کارایی میشود. محبوبیت محاسبات همه منظوره در پردازندههای گرافیکی یا همان GPGPU به دلیل قابلیت محاسباتی بالای آن در اجرای برنامههای موازی و همزمان و همچنین مدلهای برنامه نویسی پردازندههای گرافیکی همه منظوره مانند CUDA و Open CL، دریچههای جدیدی را به سوی ارتقاء سرعت برنامههای کاربردی همه منظوره گشودهاند. از سوی دیگر، امروزه روز به روز بر اهمیت تبادل داده بین GPGPUها و پردازندهها افزوده میگردد. این تحقیق یک طرح مدیریت کش GPGPU مقاوم در برابر سربار مفرط ناشی از تعویض کش با اجتناب از ناسازگاری آگاه از جریان (SACAT) را پیشنهاد نموده است که بهصورت کارایی از منابع کش GPGPU استفاده نموده و تمامی مسائل مربوط به کش های GPGPU را مرتفع میسازد. طرح پیشنهادی از سه تکنیک متعامد مختلف استفاده میکند. اولی بهصورت پویا و دقیق، جریانهای برنامههای کاربردی را تشخیص داده و آنها را عبور میدهد. دومی، یک کنترلکننده دریچه تار(ریسمان) با نمونهبرداری از هستهها (DWT-CS) است که برای کاهش میزان سربار مفرط ناشی از تعویض کش مورداستفاده قرار میگیرد. DWT-CS بهصورت یک جستجوی فراگیر بر روی هستهها جهت یافتن بهترین تعداد نخها جهت رسیدن به بالاترین کارایی استفاده میشود. سومی، استفاده از یک کش جایگذاری شبه تصادفی (PRIC) است که یک تابع شاخص گذاری کش توسعهیافته بر مبنای نگاشت چندجملهای می باشد که برای کاهش وابستگیها و از بین بردن تضادها، مورد استفاده قرار میگیرد. نتایج آزمایشات نشان میدهند که روش پیشنهادی تحقیق میتواند به ترتیب به اندازه منجر به بهبود کارایی نسبت به روشهای زمانبند جبهه موج متوالی کش (CCWS) و بافر اولویتبندی درخواستهای حافظه (MRPB) شود.
کلمات کلیدی: پردازنده گرافیکی همه منظوره (GPGPU)، GPU، حافظه پنهان(کش)، SACAT.
1.مقدمه
در سالهای اخیر، علاقه نسبت در اختیار گرفتن قدرت سختافزار گرافیکی به منظور انجام محاسبات موازیهمهمنظوره که اصطلاحا این محاسبات”پردازندههای گرافیکی همه منظوره”( GPGPU) نیز نامیده میشود به سرعت افزایش یافته است. پردازندههای توان عملیاتی محور، مانند واحدهای پردازش گرافیکی همهمنظوره (GPGPUs) بهصورت گستردهای برای سرعت بخشیدن به برنامههای کاربردی موازی با دادههای محاسباتی فشرده، استفاده میشوند زیرا دارای کارایی و توان محاسباتی بالایی هستند. با اینحال برنامهنویسی GPGPU، کار دشواری است. برنامهنویس مجبور است که بهصورت صریح حافظه چرکنویس تراشه را کنترل نماید تا بتواند امکان دسترسی به حافظه ادغامشده و بهکارگیری محلی دادهها را فراهم سازند. علاوه بر این، نشان داده شده است که توان عملیاتی حافظه یک فاکتور محدود برای کارایی بسیاری از برنامههای کاربردی GPGPU است. برای حل این مشکلات، GPUهای مدرن توسط یک کش همهمنظوره مجهز شدهاند که برای کاهش تقاضای پهنای باند خارج از تراشه، افزایش توان عملیاتی سیستم حافظه، بهبود کارایی برخی از برنامههای کاربردی GPGPU نامنظم و افزایش قابلیت برنامهریزی GPU تلاش میکنند]3،2،1[.
اندازه کش GPU در مقایسه با تعداد نخهای فعال یک GPU در حال اجرا، بسیار محدودتر است. GPU فرمی NVIDIA، از 1536 نخ فعال برای هر هسته پشتیبانی میکند و اندازه کش L1 آن بین مقادیر 16 تا 48 کیلوبایت قابل پیکربندی است. ازاینرو، ظرفیت کش L1 برای هر نخ برابر 10 یا 32 بایت خواهد بود که کمتر از مقدار اندازه خط کش واحد (128 بایت) است]4[.
این رفتار در GPU کپلر NVIDIA نیز قابلمشاهده است که دارای 2048 نخ فعال برای هر هسته است و کش داده L1 فقط خواندنی آن ، دارای سایز 48 کیلوبایتی است. این مسئله نشان میدهد که کشهای GPU برای نگهداشتن مجموعههای کاری هر نخ طراحی نشدهاند]5[.
برای مثال، CPU هفت هستهای اینتل شامل 2 نخ و یک کش L1 سیودو بایتی است( یعنی 16 کیلوبایت برای هر نخ). در واقع، کش های GPU برای استفاده از برخی الگوهای دسترسی طراحی شدهاند که دارای فضای کش کمی برای هر نخ هستند]6[.
از اینرو زمانی که برنامههای کاربردی GPGPU با فضای کش بزرگ برای هر نخ وجود داشته باشند و بر روی استفاده از موقعیت دادهها تکیه کنند، آنگاه نخهای فعال برای تعداد کمی از خطوط کش موجود، محاسبه میشوند و کش L1 در معرض سربار مفرط تعویض کش قرار خواهد گرفت. علاوه بر این، تعداد محدود وابستگی مجموعهها(معمولاً بین 4 تا 6،) منجر میشود که کش L1 در معرض آسیب خطاهای ناسازگاری و وابستگیها باشد. علاوه بر این، برنامههای کاربردی GPGPU که از حافظههای چرکنویس استفاده میکنند و برای استفاده از محل، یک رفتار اجرا(جریان) را بر روی کش L1 به نمایش میگذارند. طرحهای مدیریت کش که معمولاً از این جریان برنامههای کاربردی ناآگاه هستند منجر به ایجاد ارتباطات بی فایده و بیهدف در کش L1 شده و در نتیجه کارایی را بهصورت چشمگیری کاهش میدهند]7[.
تکنیکهای مختلفی برای کاهش میزان سربار مفرط تعویض کش ارائه شده است که برخی موارد شامل دریچه کنترل CTA ]9،8[، دریچه کنترل نخ ]13،12،11،10[ و بافر FIFO ]14[ و سیاست جایگزینی کش مقاوم در برابر سربار مفرط تعویض کش ] 16،15،12[ هستند. با اینحال، بسیاری از این تکنیکها تنها مسئله سربار مفرط تعویض کش را حل میکنند. ولی با این حال سربار ذخیرهسازی زیادی در آنها رخ میدهد که نیازمند تغییرات اساسی در معماری پایه بسیاری از تجهیزات است. در سوی دیگر گذرگاه فرعی کش ] 14،13،12[ برای کاهش میزان وابستگی پیشنهاد شده است. با اینحال، گذرگاه فرعی کش از منابع کش در دسترس بهخوبی استفاده نمیکند. در بسیاری موارد، استفاده از گذرگاه فرعی زمانی انجام میشود که بسیاری از مجموعههای کش بدون استفاده هستند. این تحقیق به معرفی یک راهکار مدیریت کش GPGPU مقاوم در برابر سربار مفرط تعویض با اجتناب از ناسازگاری آگاه از جریان پرداخته که بهصورت کارایی از منابع کش GPGPU استفاده میکند. طرح پیشنهادی از سه تکنیک استفاده میکند. اولی بهصورت پویا و دقیق، جریانهای برنامههای کاربردی که بین کش L1 و L2 رخ میدهند را شناسایی کرده و عبور میدهد. دومی، یک کنترلکننده دریچه نخ با نمونهبرداری از هستهها (DWT-CS) است که برای کاهش میزان سربار مفرط تعویض کش مورداستفاده قرار میگیرد. DWT-CS، MPKI را در L1 تحت نظارت قرار داده و تعداد نخها در هر هسته GPU را نمونهبرداری میکند. پسازآن نخهای فعال برای تمامی هستهها بر اساس تعداد نخهای متناظر با هسته برنده تنظیم میشوند (هسته برنده هستهای است که دارای بالاترین کارایی در طول دوره نمونهبرداری است). در نهایت، یک تابع شاخص گذاری کش بهبود یافته با نام کش جایگزینی شبه تصادفی (PRIC) نیز پیشنهاد شده است. این روش مبتنی بر نگاشت چندجملهای ]17[ است و برای کاهش میزان وابستگی و کاهش خطاهای ناسازگاری مورد استفاده قرار میگیرد. PRIC بهصورت نیمه تصادفی و منصفانه، دستیابیها به حافظه را بین مجموعههای کش، توزیع نموده و درنتیجه بهصورت کارایی از منابع کش استفاده میکند. این اولین روشی است که سه مسئله مهم کش های GPGPU که شامل وابستگی، سربار مفرط تعویض و رفتار جریان هستند را حل میکند. نتایج آزمایشات نشان میدهند که روش پیشنهادی نیازمند سختافزارهای مشابهی بوده و قادر به دستیابی به میانگین هارمونیک 1.8 و 1.5 برابر نسبت به روشهای زمانبند جبهه موج متوالی کش (CCWS) و روش بافر اولویتبندی درخواستهای حافظه (MRPB) هستند. علاوه بر این، در این تحقیق یک متدولوژی توصیف صفات اختصاصی برای آنالیز و اندازهگیری تعداد موقعیتهای موجود دربارهای کاری GPGPU ارائه میشود که از کش نامحدود کاملاً وابسته برای این کار استفاده میشود. نتایج نشان میدهند که بسیاری از برنامههای کاربردی GPGPU دارای مجموعههای کاری بزرگ و یا تکنیک استفاده مجدد ضعیفی برای استفاده از کش هستند و در نتیجه از سلسلهمراتب کش نمیتوانند بهرهمند شوند. در سوی دیگر، برخی از برنامههای کاربردی GPGPU دارای سطح بالایی از ارتباطات وابسته و یا سربار مفرط تعویض کش هستند.
توجه:
برای دانلود فایل کامل ورد لطفا اقدام به خرید نمایید.
لینک دانلود فایل بلافاصله پس از خرید بصورت اتوماتیک برای شما ایمیل می گردد.
به منظور سفارش تحقیق مرتبط با رشته تخصصی خود بر روی کلید زیر کلیک نمایید.
سفارش تحقیق






دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.