توضیحات
عنوان فارسی: موازی سازی پیوندهای ساختاری برای پردازش پرس و جوها روی داده های XML بزرگ با استفاده از Map Reduse (نگاشت کاهش)
عنوان انگلیسی مقاله ترجمه شده:
Parallelizing Structural Joins to Process Queries over Big XML Data Using MapReduce
چکیده:
پردازش پرس و جوهای XML داده های خیلی بزرگ XML با استفاده MapReduse در سالهای اخیر مطالعه شده است.با این حال،آثار موجود روی پارتیشن بندی اسناد XML و توزیع قطعات XML به گرههای محاسباتی مختلف تمرکز دارند. این تلاش ممکن است سربار بالا در انتقال قطعه XML از یک گره به دیگری در طول اجرای MapReduseرا معرفی کند. با الحاق ساختاری بر اساس رویکرد پردازش پرس و جو XML تحریک ( بر انگیخته) میشود. که تنها لیست های معکوس مربوط به پردازش پرس وجوها استفاده می شوند برای اینکه هزینه I/O (ورودی/ خروجی) را کاهش دهند.ما یک تکنیک جدید برای استفاده از MapReduse برای توزیع برچسبها در لیستهای معکوس در یک خوشه محاسباتی پیشنهاد می کنیم.به طوری که الحاقهای ساختاری می توانند به طور موازی انجام شوند تا پرس و جوها را پردازش کنند. ما همچنین، برای کاهش فضای محساباتی در چارچوبمان و به منظور بهبود عملکرد پردازش پرس و جو یک تکنیک بهینهسازی پیشنهاد می کنیم. در نهایت ما ، آزمایش می کنیم تا الگوریتم هایمان را معتبر کنیم.
مقدمه
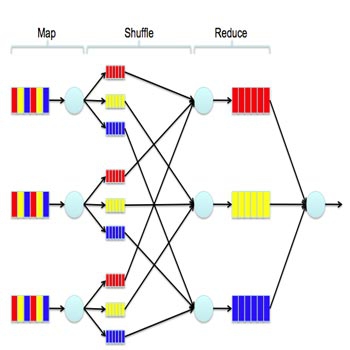
افزایش میزان اطلاعات تولید شده توسط برنامه های مختلف و افزایش توجه به ارزش دادهها نشان از آغاز دوران داده های بزرگ است. شکی نیست که به طور موثر مدیریت داده های بزرگ گام اول برای هر تجزیه و تحلیل بیشتر و به کار گیری داده های بزرگ است. چگونگی مدیریت چنین دادههایی شامل یک چالش جدید برای جامعه پایگاه داده است. به تدریج، تلاشهای تحقیقاتی زیادی به یک چارچوب پردازش داده های توزیع شده همگرا می شود MapReduse .این مدل برنامهنویسی پردازش داده های موازی را با ارائه دو رابط تسهیل می کند. نگاشت و کاهش.با یک سیستم پشتبان سطحی روی مدیریت منبع محاسباتی، یک کاربر تنها به پیادهسازی دو تابع برای پردازش دادههای اصولی بدون مراقبت(نگرانی) در مورد توسعه، گسترش و قابلیت اطمینان سیستم نیاز دارد. کارهای گسترده ای برای پیاده سازی اپراتورهای پایگاه داده، و سیستم های پایگاه داده روی بالای MapReduse وجود دارد.اخیراً محققان به دنبال امکان مدیریت دادههای XML بزرگ در یک محیط توزیع شده بیشتر کشسان مانند هادوپ با استفاده از نگاشت کاهش(MapReduse) هستند.با الهام از سیستم پایگاه داده رابطهای ، XML فعال میشود. داده XML بزرگ توسط ذخیره سازی و اپراتورهای رابطهای، ذخیره و پردازش می شود.با این حال، خرد گرده داده های XML در اندازه بزرگ به جداول رابطه ای به شدت گران است.علاوه بر این،با ذخیره سازی رابطه ای، هر پرس و جو XML باید توسط چند پیوندθ(θjoin) بین جداول پردازش شود.هزینه برای پیوندها هنوز برای هادوپ بر مبنای سیستم های پایگاه داده تنگنا است.بیشترین تلاشهای تحقیقات اخیر وسیله نفوذ روی ایده پارتیشن بندی XML و تجزیه پرس و جو از پایگاه داده های توزیع شده XML اتخاذ کردند.شبیه به عملوند پیوند در پایگاه داده رابطه ای، یک پرس و جو XML ممکن است نیاز به اتصال دو یا چند عنصر دلخواه در سراسر سند XML داشته باشد.بنابراین برای پردازش پرسوجوهای(query) XML در یک سیستم توزیع شده انتقال دادههای قطعه قطعه شده از یک گره به دیگری اجتناب ناپذیر است. در یک محیط ایستا مانند یک سیستم پایگاه داده توزیع شده XML ،روش های شاخص گذاری مناسب می تواند به توزیع بهینه قطعات داده و حجم کار کمک کند.به هر حال برای یک محیط توزیع شده قابل ارتجاع مانند هادوپ، هر کپی از قطعه XML احتمالاً به گره های مختلف غیر قابل تعیین برای پردازش منتقل خواهد شد. به عبارت دیگر بهینه سازی توزیع داده در یک چارچوب نگاشت کاهش دشوار است، بنا براین، روش موجود ممکن متحمل هزینه بالای ورودی/خروجی و انتقال شبکه بشود.در واقع روش های مختلف برای پردازش متمرکز پرس و جو XML برای بیش از یک دهه مطالعه شده اند. یکی از نکات برجسته این است که محبوبیت پیوند ساختاری مبتنی بر رویکرد است (به عنوان مثال 6)در مقایسه با دیگر روشهای محلی، مانند روش هدایتی، و روش تطبیق توالی، یک مزیت اصلی روش پیوند ساختاری صرفه جویی روی هزینه I/O است.به طور خاص، در رویکرد پیوند ساختاری، تنها چند لیست معکوس مربوط به گره های پرس و جو از دیسک، به جای تمام گرهها در سند خوانده می شوند.مفید خواهد بود، اگر ما بتوانیم چنین روشی را در چارچوب نگاشت کاهش (MapReduse) تطبیق دهیم به طوری که ورودی/خروجی دیسک و هزینه شبکه بتواند کاهش یابد.در این مقاله، ما موازی سازی پیوند ساختاری مبتنی بر الگوریتم های پردازش پرس و جو XML با استفاده از نگاشت کاهش مطالعه میکنیم.به جای توزیع کل سند XML بزرگ به یک خوشه کامپیوتر، ما لیستهای معکوس را برای هر نوع گره سند که پرس و جو می شود توزیع می کنیم.
از آنجا که اندازه لیست معکوس که برای پردازش پرس و جو استفاده می شود بسیار کوچکتر از اندازه کل سند XML است، رویکرد ما به طور بالقوه باعث کاهش هزینه در انتقال داده ها متقابل گره میشود.
توجه:
- برای دانلود فایل word کامل ترجمه از گزینه افزودن به سبد خرید بالا استفاده فرمایید.
- لینک دانلود فایل بلافاصله پس از خرید بصورت اتوماتیک برای شما ایمیل می گردد.
به منظور سفارش ترجمه تخصصی مقالات خود بر روی کلید زیر کلیک نمایید.
سفارش ترجمه مقاله





دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.