

توضیحات
عنوان فارسی: موضاعات روز (روندها) در کاوش دانش تعاملی شخصی سازی علم پزشکی: علوم شناختی در تلاقی با یادگیری ماشین
عنوان انگلیسی مقاله ترجمه شده:
Trends in Interactive Knowledge Discovery for Personalized Medicine: Cognitive Science meets Machine Learning
چکیده ( انگیزه و هدف بهره از علوم کامپیوتر)
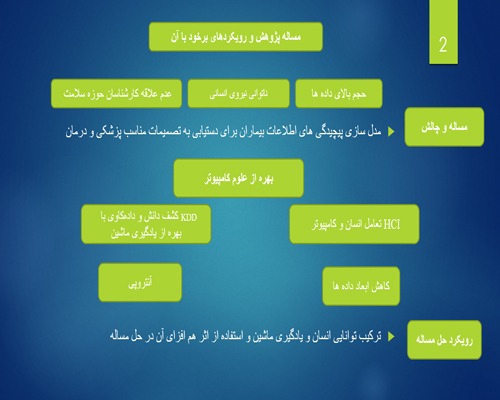
هدف مهم پزشکی مدل سازی پیچیدگی های اطلاعات بیماران برای دستیابی به تصمیمات مناسب پزشکی و درمان برای شخص بیمار است. این روند در شخصی کردن درمان، تعداد بسیار زیادی داده تولید میکند و از آنجا که در حوزه پزشکی ابعاد بالای 3 هستند نیروی انسانی نمیتواند به راحتی آنها را تحلیل کند. افزون بر آن کارشناسان حوز سلامت علاقهای به این دادهها ندارند و اطلاعات و نتایج حاصل از آنها برایشان مهم است. در نتیجه علوم کامپیوتر با به کارگیری محاسبات عددی، الگوریتمها و ابزارهای مناسب، این اطلاعات را استخراج میکند. ترکیب همافزای دو روش در دو حوزه مختلف میتواند کمک کند : تعامل انسان و کامپیوتر(HCI) و کشف دانش و دادهکاوی (KDD) با استفاده از یادگیری ماشین. روش HCI ابعاد را کاهش میدهد و با استفاده از مجموعهای از روشهای محاسباتی مانند تئوری گراف و توپولوژی جبری مساله را حل میکند. افزون بر آن دادههای پزشکی معمولا پراکنده و وابسته به زمان هستند یعنی آنتروپی هم از موضوعات مهم است.
بخش 1 : مقدمه (تعرف مساله و رویکرد حل آن)
در حوزه سلامت با حجم وسیعی از داده مواجه هستیم که مشکلاتی از جمله پیچیدگی ابعاد (مشکلات مربوط به تغییر مقیاس و نقشه برداری)، ناهمگن بودن دادهها (ترکیب دادهها)، تغییر در طول زمان، و مهم تراز همه عدم قطعیت در کیفیت دادهها و خطا و کامل نبودن دادهها دارند.
البته در یادگیری ماشین این حجیم بودن داده خوب است چون در حوزه پزشکی تنها بررسی تعداد اندکی نمونه ممکن است به حدس تصادفی و اشتباه بینجامد.
محققان یادگیری ماشین الگوریتم ایی را مطالعه میکنند که بتواند از دیتاها یاد بگیرد. و از آنجا که یادگیری جنبه مهم رفتار هوشمندانه است یادگیری ماشین جنبه مهم و هستهای هوش مصنوعی شده است. واضحترین مثال یادگیری در انسان رخ میدهد بنابراین یک پل طبیعی بین یادگیری ماشین و علوم تشخیصی که شدیداً با HCI مرتبط است، وجود دارد.
یک رویکرد جدید این است که بجای اینکه برای پاسخ به سوال مطرح شده داده جمع آوری کنیم، برای دادههای موجود سوال طرح کنیم. چالش مهم در این رویکرد این است که سؤالهای مرتبط برای دریافتن الگوهای ساختاری مرتبط و یا الگوهای زمانی (اطلاعات) در چنین دادههایی پرسیده شود زیرا این اطلاعات مخفی بوده و در دسترس کارشناسان نیستند.
در این مقاله : در فصل 2 تعدادی از مفاهیم کلیدی به طور مختصر توضیح داده میشوند. در فصل 3 ایده پایهای رویکرد HCI-KDD به همراه هفت حوزه تحقیقاتی در این زمینه بیان شده است. به سه حوزه از این هفت حوزه ها در فصلهای بعدی پرداخته میشود. در فصل 4 دادهکاوی بر پایه گراف، در فصل 5 دادهکاوی توپولوژیکی و در فصل 6 دادهکاوی بر پایه آنتروپی. در نهایت نتیجه گرفته میشود که ترکیب روشهای اشاره شده کارامد است.
بخش 2 : رویکرد HCI-KDD
رویکرد HCI-KDD یک ترکیب همافزای سودمند از روشها و رویکردهای دو حوزه است که شرایط ایده آل برای حل برخی از مشکلات دادههای حجیم که در بالا اشاره شد فراهم میکند :HCI و KDD .
در این رویکرد کاری که انسان میتواند بهتر انجام دهد و کاری که کامپیوتر میتواند بهتر انجام دهد در کنار هم قرار دارد. مثال خوبی برای نشان دادن قدرت انسان در مقابل کامپیوتر GO (بازی 2000 ساله چینی) است که هنوز برای کامپیوترها یک چالش است. انسانها در تشخیص الگو در فضاهایی با بعد کم بسیار خوب عمل میکنند. علیرغم اینکه انسان سه بعد فضا را به طور مستقیم نمیبیند با تجسمهای دو بعدی این کار انجام میشود.
کرنلها در یادگیری ماشین با درک مسایل، عمومیسازی و سادهسازی در علوم تشخیصی دارند. بیشتر اندازهگیریهای شباهت که توسط روانشناسان انجام میشود مثالهایی از تعریف مثبت کرنل است که برای آنها یک تئوری ریاضیاتی موجود است. در نتیجه روشهای کرنل میتوانند روشهای تئوری همسان کننده باشند که نشان میدهند چگونه چند تئوری رقیب و به ظاهر نامتناسب در علوم تشخیصی میتوانند در کنار هم قرار داده شوند.
مسلما مشکل یادگیری مسیری به فهم هوش در مغز و ماشین برای فهم این که مغز انسان چگونه کار میکند و توسعه الگوریتمهای هوشمند که از داده یاد میگیرند و بهبود آنها باز میکند همانند چیزی که در کودکان رخ میدهد.
از طرف دیگر کامپیوتر میتواند تحلیل دادهها را در ابعاد بالا به خوبی انجام دهد که باعث میشود از توپولوژی محاسباتی از طریق جایگزینی مجموعهای از نقاط داده ابری با مجتمع سادگی (simplicial complex) استفاده کنیم که داده را به یک شی توپولوژیک جهانی تغییر میدهد. ترکیب این هوشهای مطلوب در فرایند کشف اطلاعات بسیار مفید است.
اصل ایده HCI-KDD ترکیب جنبههای بهترینهای دو دنیا است: تعامل انسان و کامپیوتر با تاکید بر فهم، شناخت، تعامل، منطق، تصمیمگیری، یادگیری انسانی و هوش انسانی و اکتشاف اطلاعات/ دادهکاوی شامل پردازش داده، آمار محاسباتی، هوش مصنوعی و مخصوصا یادگیری ماشین تجمعی. مهمترین جنبه این است که در این چرخه انسان حضور دارد. بسیاری از حوزه ها به ویژه حوزه پزشکی نمیتواند کاملا اتوماتیک شود. اطلاعات کارشناس حوزه سلامت ارزش زیادی دارد پس آنها میتوانند از مجموعه دادهشان سوال بپرسند. یک مثال در زمینه رادیولوژی است.
اطلاعات مفید بالینی در یک عکس به طور معمول شامل تغییرات خاکستری در مناطق بسیار موضعی تصویر اشعه ایکس است و استخراج چنین مناطقی با تکنیکهای پردازش تصویر استاندارد مشکل سختی است. آوردن پزشک در کار به این معنی است که او مناطق پاتولوژیک و مجموعهای از نشانههای تشریح را در عکس تعیین کند. ابزارهای سطح پایین کامپیوتری و الگوریتمهای پردازش تصویر میتواند برای این مناطق تعیین شده، برای استخراج خواص مربوط به تغییرات در مقیاس خاکستری لحاظ شود. در رویکرد HCI-KDD هفت حوزه تحقیقاتی مهم میتواند در نظر گرفته شود. حوزه 1 : تجمع داده(ترکیب داده و نقشه برداری داده)، حوزه 2 : الگوریتمهای کاوش و حوزه 6 : تجسم داده. چهار حوزه دیگر که در این مقاله به آنها میپردازیم. در حوزه زیست پزشکی (حفظ حریم شخصی، حفاظت از داده، ایمنی و امنیت) الزامی است.
فصل 3 : دادهکاوی بر اساس گراف
گرافها مدتهاست در علوم زیستی استفاده میشوند. ترکیب نظریه گراف و یادگیری ماشین و تحلیل آماری داده منجر به ایجاد زمینه جدید تحلیل شبکه برای کشف دادههای گراف پزشکی میشود. نسلهای بزرگ مقیاس ژنومیکس، پروتئومیکس و … و علامتدهی داده منجر به ایجاد شبکههایی میشود که چارچوبی جدید برای درک پایه مولکولی حالتهای فیزیولوژیک و پاتولوژیک فراهم میکند. شبکه و روشهای بر پایه شبکهها برای مشخصه یابی مکانیسمهای ژنومیکی و ژنتیکی و همچنین پیامرسانی پروتئینها به کار رفته است: بیماریها به عنوان آشفتگیهای غیرعادی شبکههای سلولی مورد بررسی قرارگرفتهاند. وقتی یک سیستم با یک گراف یا شبکه نشان داده میشود، روشهای نظریه گراف میتوانند برای یافتن دستاوردهای جدید استفاده شوند. روشهای آماری و یادگیری ماشین مختلفی به این منظور توسعهیافتهاند و در شبکهها استفاده میشوند. نقشه برداری از فضاهای اطلاعاتی موجود و تایید شده به عنوان یک گراف انتزاعی و سپس یک تحلیل تصویری و نظریهای گراف میتواند دید جدیدی به الگوهای پنهان در دادهها که در راستای اکتشاف اطلاعات است ایجاد کند.
اولین سوال این است که چگونه گراف را به دست آوریم یا به طور سادهتر چگونه مجموعه نقاط را به دست آوریم؟ چون مجموعه نقطههای داه ابری میتواند به عنوان آغازگر برای چنین رویکردهایی استفاده شود. پاسخ به این سوال بیهوده نیست. غیر از نقاط ابری که به طور طبیعی در دسترس هستند مثلا از اسکنرهای لیزری یا ساختارهای پروتئین. با توجه به مثال قبلی گرافها حاوی اطلاعات بیشتری نسبت به کلمات و عبارات هستند.
5 پایه تئوری برای دادهکاوی بر اساس گراف وجود دارد : 1) دستهبندیهای زیر گرافها 2) زیر گرافهای همانند 3) ویژگیهای گراف 4) اندازهگیریهای کاوشگر و 5) روشهای حل.
یک کاربرد رویکرد نظریه گراف تحلیل متنی وب و شبکههای اجتماعی برای شناسایی بیماریهای شبیه آنفولانزا است. افزون بر آن در میان مفاهیم زیستی، ژنها، پروتئینها و داروهای توسعه یافته با داده متنی کاوی توپولوژیک شبکههای ارتباط پرمحتوایی میتواند وجود داشته باشد. شبکه پزشکی کاربرد بالینی زمینه متنکاوی توپولوژیک را (با توجه به پرداختنش به پیچیدگی بیماریهای انسانی با نقشههای شبکهای مولکولی و فنوتیپ) توصیف میکند.
مثال اخیر پگاسوس (PEGASU ) است. یک کتابخانه منبع باز گراف کاوی که وظایف گراف کاوی معمولی مانند محاسبه قطر گراف، شعاع هر گره یافتن اجرای مرتبط را انجام میدهد. بسیاری از عملیات گراف کاوی(تخمین قطر، اجزای مرتبط و …) یک ضرب تکراری ماتریس-بردار هستند. در پگاسوس نویسندگان از یک تکرار ضرب ماتریس-بردار ابتدایی و تعمیم یافته که بهینه شده است و به عملکرد خوبی دست یافته، استفاده کردهاند.
توجه:
- برای دانلود فایل word کامل ترجمه از گزینه افزودن به سبد خرید بالا استفاده فرمایید.
- لینک دانلود فایل بلافاصله پس از خرید بصورت اتوماتیک برای شما ایمیل می گردد.
به منظور سفارش ترجمه تخصصی مقالات خود بر روی کلید زیر کلیک نمایید.
سفارش ترجمه مقاله




دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.