توضیحات
عنوان فارسی: تشخیص کاراکتر با استفاده از شبکه عصبی
عنوان انگلیسی مقاله ترجمه شده:
Character Recognition Using Neural Network
چکیده
در این مقاله ، ما از شبکه های عصبی برای تشخیص کاراکتر استفاده میکنیم. در این مقاله استراتژی های برون خطی برای کاراکتر دست نویس انگلیسی (A TO Z) و (0 to 9) توسعه یافته اند.این روش، روش تشخیص کاراکتر را بهبود می بخشد. در پیش پردازش کاراکتر از دو دویی سازی، آستانه گذاری و روش تقسیم بندی استفاده می شود. روش پیشنهادی بر اساس استفاده از روش پس انتشار فید فوروارد برای طبقه بندی کاراکتر است. ANN(شبکه عصبی مصنوعی) با استفاده از الگوریتم پس انتشار خطا آموزش داده شده است. در سیستم پیشنهادی، کاراکترهای عددی انگلیسی با اعداد دو دویی نشان داده شده اند که به عنوان ورودی استفاده می شوند و سپس آنها را به یک شبکه عصبی مصنوعی تغذیه شدند. شبکه عصبی با الگوریتم پس از انتشار ادامه می یابد که شامل آموزش میباشد.
پیش گفتار
تشخیص دست خط بدون شک یکی از چالش برانگیز ترین مناطق تشخیص الگو میباشد . که در یک طیف گسترده ای از مسائل عملی دنیای واقعی، از جمله تجزیه و تحلیل اسناد و مدارک، تفسیر آدرس پستی ، پردازش چک بانکی، تایید امضا، تأیید سند و مواردی دیگر بی نهایت مفید است[1] . روشهای مختلف تشخیص الگو برای تشخیص دست خط آنلاین و آفلاین ، از جمله روش های آماری، روش های ساختاری و نحوی و شبکه های عصبی استفاده شده اند. برخی از سیستم های خواندن، ضربه قلم را شناسایی میکنند؛ دیگر سیستمها سعی می کنند کاراکترها، گروهی از کاراکترها، و یا کل کلمات را شناسایی کنند.
شبکه های عصبی از عناصر ساده تشکیل شده اند که به صورت موازی عمل میکنند. این عناصر از سیستم عصبی بیولوژیکی الهام گرفته شده اند. همانطور که در طبیعت، عملکرد شبکه تا حدود زیادی با ارتباط بین عناصر تعیین می شود. ما می توانیم به یک شبکه عصبی آموزش انجام یک تابع خاص را با تطبیق مقادیر ارتباطات (وزن) بین عناصر بدهیم. شبکه های عصبی معمولا تنظیم شده، و یا آموزش دیده، هستند به طوری که یک ورودی خاص، منجر به یک خروجی خاص هدف میشود.چنین وضعیتی در زیر نشان داده شده است. که در آن ، شبکه بر اساس یک مقایسه ی خروجی و هدف، تا زمانی که خروجی شبکه منطبق بر هدف شود، تنظیم شده است. معمولاً بسیاری از این چنین جفتهای ورودی/هدف ،در این یادگیری تحت نظارت، برای آموزش یک شبکه استفاده میشوند.
پردازش سند کامپیوتری شده به دلیل افزایش حجم نمایی اسناد روزانه و سیستم های کامپیوتری قوی تر و مقرون به صرفه تر ، به سرعت از سال 1980 در حال رشد بوده است. به طور مستقیم، تبدیل بلوک های متنی به کدهای ASCII نشان دهنده یکی از مهم ترین اعمال در پردازش سند میباشد. [5] استراتژی ما برای طبقه بندی مجدد کاراکترها ، ترکیب تجزیه و تحلیل ساختار تایپی که کاراکترها را مشخص میکند در مرحله اول میباشد، و در نتیجه محدوده تشخیص کاراکتر را کاهش می دهد.
مرتب سازی پستی خودکار و پردازش چک بانکی خودکار از کاربردهای تشخیص کاراکتر هستند. در این مقاله کار بر روی تشخیص کاراکتر مرور شده است. تشخیص کاراکتر نوری (OCR) برای تشخیص کاراکترهای چاپی و دست نویس استفاده می شود. روش های متعددی برای حل مسئله وجود دارد که در ویژگی های استخراج شده از نمایش گرافیکی کاراکترها متفاوت میباشند.
تاریخچه
تشخیص کاراکتر نوری اولیه را می توان به فعالیت در اطراف دو موضوع ترسیم کرد: گسترش تلگراف و ایجاد دستگاه های خواندن برای نابینایان. در سال 1914، Emanuel Goldberg ماشینی توسعه داد که حروف را میخواند و آنها را به کدهای تلگراف استاندارد تبدیل میکرد. در همان زمان، Edmund Fournier تلفن نوری (optophone) را توسعه داد، یک اسکنر دستی که با عبور از روی یک صفحه چاپ شده ، صداهایی متناسب با حروف و کاراکترها تولید میکرد.
پس از آن، او عکاسی از پرونده داده ها و بعد، استفاده از سلولهای نوری، مطابقت تصاویر با یک قالب که شامل الگوی شناسایی مورد نظر بود را پیشنهاد کرد. Paul W Handel. نیز حق ثبت اختراع در زمینه این فناوری مطابقت نمونهOCR در ایالات متحده آمریکا در سال 1933 را به دست آورد.
در سال 1949 مهندسان RCA روی اولین کامپیوتر نوع OCR ابتدایی برای کمک به افراد نابینا برای اداره کهنه سربازان آمریکا کار میکردند. این دستگاه گزارش های تایپ شده را به کارت های پانچ شده برای ورود به کامپیوتر در بخش اشتراک مجله برای کمک به فرآیند حمل و نقل 20 میلیون کتاب در سال تبدیل میکرد. در حدود سال 1965، Reader’s Digest و RCA برای ساخت یک سندخوان OCR طراحی شده در سال 1965 همکاری کردند.
پیش پردازش تصویر:
فاز اول در روند تشخیص کاراکتر ما تبدیل تصویر به تصویر دو دویی توسط آستانه سازی تصویر کاراکتر داده شده است. دو مقدار شدت برای تصویر دو دویی در دسترس هستند. این مقادیر سیاه و سفید هستند. ما از صفر برای سیاه و یک برای سفید استفاده میکنیم. بنابراین رنگ کاراکتر سفید و پس زمینه سیاه میباشد.
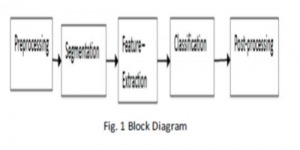
تکنیک های پیش پردازش در تصاویر اسناد رنگی، با رنگ خاکستری و یا دو دویی حاوی متن و / یا گرافیک مورد نیاز هستند. در سیستم های تشخیص کاراکتر بسیاری از برنامه های کاربردی از تصاویر خاکستری یا دو دویی استفاده میکنند چون پردازش تصاویر رنگی از لحاظ محاسباتی سنگین است [5] .چنین تصاویری همچنین ممکن است حاوی پس زمینه غیر یکنواخت و یا چاپ سفید باشند که کار را دشوار میکنند؛ نتیجه مورد نظر از پردازش یک تصویر دو دویی است که فقط شامل متن است. بنابراین، برای رسیدن به این، چند مرحله مورد نیاز است، اول، برخی از تکنیک های بهبود تصویر برای حذف نویز و یا اصلاح کنتراست در تصویر، دوم، آستانه سازی برای حذف پس زمینه شامل هر گونه صحنه، چاپ سفید و یا نویز، سوم، تقسیم بندی صفحه به گرافیک جداگانه از متن، چهارم، تقسیم بندی کاراکتر به کاراکتر های جدا از یکدیگر و در نهایت، پردازش مورفولوژیکی به منظور بهبود کاراکترها در مواردی که آستانه سازی و یا تکنیک های پیش پردازش دیگر ، بخش هایی از کاراکترها را از بین برده و یا به آنها پیکسل اضافه کرده اند. تکنیک های فوق تنها تعداد کمی از مواردی که ممکن است در سیستم های تشخیص کاراکتر و در برخی برنامه های کاربردی استفاده شوند را بیان میکند؛ برخی از این تکنیک ها و یا دیگران ممکن است در مراحل مختلف سیستم OCR استفاده شوند.
توجه:
- برای دانلود فایل word کامل ترجمه از گزینه افزودن به سبد خرید بالا استفاده فرمایید.
- لینک دانلود فایل بلافاصله پس از خرید بصورت اتوماتیک برای شما ایمیل می گردد.
به منظور سفارش ترجمه تخصصی مقالات خود بر روی کلید زیر کلیک نمایید.
سفارش ترجمه مقاله





دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.