

توضیحات
تحقیق یادگیری متریک برای خوشه بندی سلسله مراتبی
چكيده
پردازش اطلاعات و استخراج ویژگی ها نیازمند دسته بندی و خوشه بندی اطلاعات می باشد که این بخش زمانی که حجم و کاربری اطلاعات بالا برود بهتر ضرورت خود را خاطر نشان می سازد. شیوه های مختلف دسته بندی و خوشه بندی در این مقوله مورد بررسی قرار میگیرد. یکی از اصول تطبیق و بهبود رفتار سیستم ها در هر بستری، آماده سازی و تعریف سیستم به صورت مختص آن شرایط می باشد. بنابراین با استفاده از الگوریتم های یادگیری متریک در این دسته بندی ها و خوشه بندی ها می توان سیستم را تطبیق پذیر و پویا به عمل آورد. در این زمینه مقالات متعددی بررسی گردیده است و ماهیت آن ها در این نوشتار گنجانده شده است.
مقدمه – خوشه بندی
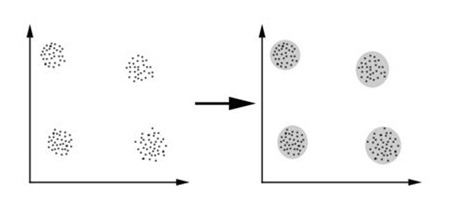
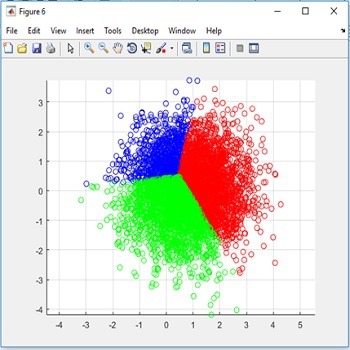
داده و الگو یکی از شاخص های بسیار مهم در دنیای اطلاعات هستند. خوشه بندی یکی از بهترین روش هایی است که برای کار با داده ها ارائه شده است. قابلیت آن در ورود به فضای داده و تشخیص ساختار آنها، خوشه بندی را یکی از ایدهآل ترین مکانیزمها برای کار با دنیای عظیم داده ها کرده است. اولین بار ایده ی آن در دهه ی ۱۹۳۵ ارائه شد و امروزه با پیشرفت ها و جهشهای عظیمی که در آن پدید آمده، خوشه بندی در کاربردها و جنبههای مختلفی حضور یافته است. خوشه بندی یکی از شاخه های یادگیری بدون نظارت میباشد و فرایند خودکاری است که در طی آن، نمونه ها به دسته هایی که اعضای آن مشابه یکدیگر می باشند تقسیم می شوند که به این دسته ها خوشه گفته میشود. بنابراین خوشه مجموعه ای از اشیاء می باشد که در آن اشیاء با یکدیگر مشابه بوده و با اشیاء موجود در خوشه های دیگر غیر مشابه میباشند. برای مشابه بودن می توان معیارهای مختلفی را در نظر گرفت مثلاً می توان معیار فاصله را برای خوشه بندی مورد استفاده قرار داد و اشیائی را که به یکدیگر نزدیکتر هستند را به عنوان یک خوشه در نظر گرفت که به این نوع خوشه بندی، خوشه بندی مبتنی بر فاصله نیز گفته می شود. به عنوان مثال در شکل 1‑1 نمونه های ورودی در سمت چپ به چهار خوشه مشابه شکل راست تقسیم می شوند. در این مثال هر یک از نمونه های ورودی به یکی از خوشه ها تعلق دارد و نمونه ای وجود ندارد که متعلق به بیش از یک خوشه باشد.
در اینجا قصد داریم روش های مختلف خوشه بندی را مورد بررسی قرار دهیم. از جمله این روشی ها، خوشه بندی K-Means ، SOM ، چگال ، FCM و سلسله مراتبی است.
…
فهرست مطالب تحقیق یادگیری متریک برای خوشه بندی سلسله مراتبی
- 1 فصل اول مقدمه – خوشه بندی.. 1
- 1.1 تعریف خوشه بندی.. 3
- 1.2 مزایای خوشه بندی.. 4
- 1.3 روش خوشه بندی K-Means. 4
- 1.3.1 مشکلات روش خوشه بندی K-Means. 5
- 1.4 خوشه بندی فازی C-Means: 6
- 1.5 روش خوشه بندی چگال: 7
- 1.6 روش خوشه بندی SOM… 7
- 1.6.1 شبکه (لایه) کوهونن.. 8
- 1.7 خوشه بندی بر پایه مدل.. 10
- 1.7.1 مزایای اصلی خوشه بندی مبتنی بر مدل.. 11
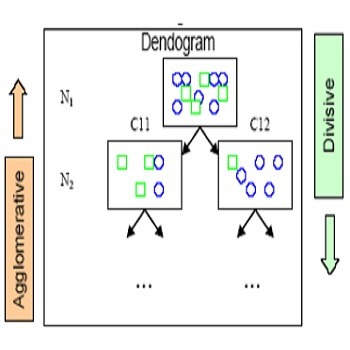
- 1.8 خوشه بندی سلسله مراتبی.. 11
- 1.8.1 بالا به پایین یا تقسیم کننده 12
- 1.8.2 پایین به بالا یا متراکم شونده 12
- 1.9 ارزیابی مدل های خوشه بندی: 14
- 1.9.1 ارزیابی جهتدار بودن خوشهها 15
- 1.9.2 ارزیابی تعداد خوشهها 15
- 1.9.3 ارزیابی کیفیت خوشهها 16
- 2 فصل دوم یادگیری متریک در خوشه بندیکارهای انجام شده. 17
- 2.1 جمع آوری اطلاعات ممتاز با یادگیری متریک… 20
- 2.2 استخراج محدودیت های لینک مستقیم از اطلاعات ممتاز 21
- 2.3 یادگیری متریک برای خوشه بندی سند سلسله مراتبی.. 23
- 2.4 روش فعالانه مبتنی بر اعتماد. 26
- 2.5 روش آموزش غیر خطی متریک فاصله. 27
- 2.6 محدودیت در حدود بالایی به عنوان یک متریک… 30
- 3 فصل سوم نتیجه گیری.. 33
- منابع و مراجع.. 35
منابع تحقیق یادگیری متریک برای خوشه بندی سلسله مراتبی
M. Nogueira, Y.K.B. Tomas, R.M. Marcacini. “Integrating distance metric learning and cluster-level constraints in semi-supervised clustering”, 2017 International Joint Conference on Neural Networks (IJCNN).
Han, J., Kamber, M., & Pei, J. (2011). Data mining: concepts and techniques (3rd ed.). Morgan Kaufmann Publishers.
Michael Greenacre, (2008). Correspondence Analysis and Related Methods. Department of Statistics, Stanford University.
C. Dunn (1973): “A Fuzzy Relative of the ISODATA Process and Its Use in Detecting Compact Well-Separated Clusters”, Journal of Cybernetics3: 32-57
C. Bezdek (1981): “Pattern Recognition with Fuzzy Objective Function Algoritms”, Plenum Press, New York
B. MacQueen (1967): “Some Methods for classification and Analysis of Multivariate Observations, Proceedings of 5-th Berkeley Symposium on Mathematical Statistics and Probability”, Berkeley, University of California Press, 1:281-297
P. Dempster, N.M. Laird, and D.B. Rubin (1977): “Maximum Likelihood from Incomplete Data via theEM algorithm”, Journal of the Royal Statistical Society, Series B, vol. 39, 1:1-38
Osmar R. Zaïane (1999), “Principles of Knowledge Discovery in Databases – Chapter 8: Data Clustering”, University of Alberta.
Khaled Hammouda, (2014). “A Comparative Study of Data Clustering Techniques”. University of Waterloo, Ontario, Canada.
Bilenko, S. Basu, and R. J. Mooney, “Integrating constraints and metric learning in semi-supervised clustering,” , 21st International Conference on Machine Learning (ICML), 2004, pp. 11–18.
Feyereisl and U. Aickelin, “Privileged information for data clustering,” Information Sciences, vol. 194, no. 0, pp. 4 – 23, 2012.
M. Marcacini and S. O. Rezende, “Incremental hierarchical text clustering with privileged information,” in ACM Symposium on Document Engineering, 2013, pp. 231–232.
Vapnik and A. Vashist, “A new learning paradigm: Learning using privileged information,” Neural Networks, vol. 22, no. 5-6, pp. 544–557, 2009.
K. Jain, “Data clustering: 50 years beyond k-means,” Pattern Recognition Letters, vol. 31, no. 8, pp. 651–666, 2010.
M. Marcacini, G. N. Correa, and S. O. Rezende, “An active learning approach to frequent itemset-based text clustering,” in 21st International Conference on Pattern Recognition (ICPR), 2012, pp. 3529–3532.
M. Marcacini, G. N. Correa, and S. O. Rezende, “An active learning approach to frequent itemset-based text clustering,” in 21st International Conference on Pattern Recognition (ICPR), 2015, pp. 3529–3532.
M. Marcacini, M.A. Domingues, E.R. Hruschka, S.O. Rezende. “Privileged Information for Hierarchical Document Clustering: A Metric Learning Approach”. 22nd International Conference on Pattern Recognition, 2014.
Mhetre, V.S. Gaikwad. “Relaxed Constraints Formulation for Non-linear Distance Metric Learning in Hierarchical Clustering”, International Journal of Computer Sciences and Engineering, April 2017.
M. Johnson, C. Xiong and J. J. Corso, “SemiSupervised Nonlinear Distance Metric Learning via Forests of Max-Margin Cluster Hierarchies,” vol. 28, no. 4, pp. 1035-1046, April 1 2016.
Mhetre, .V.S.Gaikwad, “Innovative Constraints Formulation for MaxMargin Hierarchical Clustering”, International Journal of Computer Science and Information Technology & Security (IJCSITS), July-August 2017.
Bellet, A. Habrard, and M. Sebban, ―A survey on metric learning for feature vectors and structured data,‖ arXiv preprint arXiv:1306.6709, 2013.
توجه:
تحقیق یادگیری متریک برای خوشه بندی سلسله مراتبی شامل یک فایل ورد 40 صفحه ای و یک پاورپوینت 25 اسلایدی می باشد.
لینک دانلود فایل بلافاصله پس از خرید بصورت اتوماتیک برای شما ایمیل می گردد.
به منظور سفارش تحقیق مرتبط با رشته تخصصی خود بر روی کلید زیر کلیک نمایید.
سفارش تحقیق







دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.