
توضیحات
عنوان فارسی: داده های حجیم (HADOOP)
- مقدمه
- آمار از داده ها
- هادوپ چیست
- آنچه که HADOOP ارائه می دهد
- تکنولوژی در هادوپ
- مفاهیم و طراحی HDFS
- مفاهیم و معماری MAP/REDUCE
- کشف داده های حجیم
- سیستم HPCC و تفاوت ان با HADOOP
- امنیت در HADOOP
- APACHE TEZ
- مفهوم و نسخه YARN
- نیازها در نصب
- نتیجه گیری
- منابع
مقدمه
تاریخچه big data
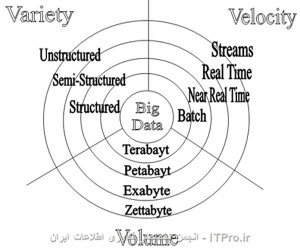
گرچه واژه big data یا داده های کلان نسبتا جدید است عمل جمع آوری مقادیر عظیم داده ها یا اطلاعات برای تحلیل های احتمالی قدمت زیادی دارد. گرچه به نظر می رسد منظور از داده های کلان فقط مقادیر عظیم داده باشد ولی big data به داده هایی اشاره دارد که علاوه بر مقدار، سرعت و تنوع فوق العاده زیادی دارد.
این مفهوم در اوایل دهه ۲۰۰۰ میلادی پدیدار شد یعنی زمانی که Doug Laney تعریف فعلی big data را با سه مشخصه زیر ارائه کرد:
- : variety تنوع یا گوناگونی
- : volumeحجم
- velocity :سرعت
: Volume مقدار ، حجم
مقدار داده ها به این واقعیت اشاره دارد که در حال تولید مقدار زیادی از این داده ها هستیم و این مقدار تولید با گذشت زمان زیادتر هم می شود. برای مثال گوشی های هوشمند دربردارنده تعدادی سنسور هستند. این سنسورها داده هایی را تولید می کنند که می توان از آنها در تحلیل استفاده کرد، به عنوان نمونه می توان سنسور GPS موبایل را مثال زد. با افزایش تعداد، پیچیدگی و استفاده از گوشیهای هوشمند مقدار داده هایی هم که تولید می کنند بیشتر می شود. سازمان ها داده ها را از منابع متعددی شامل تراکنشهای کاری، رسانه های اجتماعی و اطلاعاتی از سنسورها یا داده های ماشین به ماشین (M2M) جمع آوری می کنند. در گذشته ذخیره سازی مسئله ساز بود ولی فناوریهای جدید مانند هدوپ (Hadoop) این مشکل را حل کرده اند.
Velocity سرعت
سرعت به این معنی است که در داده های کلان، داده ها به سرعت تغییر می کنند. مثلا اطلاعات موقعیت کاربر که از گوشی هوشمند او بدست می آید به سرعت تغییر می کند. وضعیتی را در نظر بگیرید که می خواهید پیشنهاد خاصی را در خیابان خاصی به کاربر بدهید، اطلاعات موقعیت در عرض چند دقیقه یا ثانیه قدیمی و بلا استفاده می شود اگر نتوانید در موقعیت درست پیشنهاد را به مشتری بدهید نتوانسته اید از داده هایتان استفاده کنید. احتمالا حالا بهتر معنی سرعت در big data و اهمیت آن را متوجه شدید. داده ها با سرعت پیش بینی نشده تولید می شوند و باید به صورت زمانبندی شده از آن استفاده کرد. حجم زیاد داده های حاصل از تگ های [1] RFID و سنسورهای اندازه گیری هوشمند نشان می دهد که با سیلی از داده ها سروکار داریم و باید به صورت مناسبی آنها را پردازش و استفاده کنیم.
Variety تنوع
در داده های کلان، داده ها به فرمتهای مختلف و گوناگون وجود دارند. مثلا داده های ساخت یافته، داده های عددی، اسناد متنی بدون ساختار، ایمیل، ویدیو، داده های صوتی و تراکنشهای مالی در این داده ها جای دارند.
بعضی از منابع علاوه بر سه مورد فوق می توان سه بعد دیگر را برای big data در نظر گرفته اند:
Variability تغییر پذیری
علاوه بر سرعت و تنوع در حال افزایش داده ها، جزیان های داده ها می تواند بسیار ناپایدار و دارای پیکهای (اوج) دوره ای باشد. مدیریت بار داده های روزانه، فصلی و یکباره مشکل است. این مشکل وقتی بیشتر خودش را نشان می دهد که داده های غیرساخت یافته هم داشته باشیم.
Complexity پیچیدگی
در عصر فعلی داده ها از منابع مختلفی می آیند، چنین وضعیتی پیوند، تطبیق، پاکسازی و تبدیل داده ها را سخت می کند. با این وجود، اتصال داده ها و تعیین سلسله مراتب و پیوند دادها ضروری است و گرنه داده ها به سرعت از دسترس خارج می شوند.
Value – ارزش
بهترین چیزی که درباره ارزش در داده های کلان می توان گفت این است که هرچه در تحلیل داده های big data بهتر عمل کنیم. ارزش بیشتری بدست می آوریم. برای این که ارزش مناسبی از big data کسب کنیم باید توان محاسباتی کافی، قابلیتها و مهارتهای تحلیل داده مناسب را داشته باشیم.
اهمیت big data یا داده های کلان به این نیست که چه مقدار داده در اختیار داریم بلکه این مهم است که با این داده ها چه می کنیم. شما می توانید داده ها را از هر منبعی گرفته و تحلیل کنید تا بر چالشهایی مانند کاهش هزینه ها، افزایش سرعت، توسعه محصول جدید، ارائه پیشنهادهای بهینه به مشتریان و تصمیم گیری هوشمند غلبه کنید. وقتی که big data با تحلیلهای قدرتمند همراه شود کارهای بزرگی مانند موارد زیر قابل انجام می شود:
- تعیین ریشه های اصلی مشکلات و ضایعات به صورت بلافاصله و بلادرنگ.
- تشخیص رفتارهای کلاهبردارانه قبل از این که بر کسب وکار و سازمان شما تاثیری بگذارد.
- محاسبه مجدد ریسک کل پورتفولیوها در چند دقیقه.
- تولید کوپن تخفیف برای مشتری در کنار دستگاه POS بر مبنای عادات خرید مشتری.
شکل زیر از انجمن IT برای بحث داده های حجیم است.
- آمار شرکت IBM
این شرکت نشان داد که هر روز 2.5 اگزا بایت داده تولید میشود و همچنین %90 از داده ها در 2 سال اخیر تولید شده است. یک کامپیوتر شخصی حدود 500 گیگا بایت (10 به توان 9 بایت) داده نگه میدارد ، بنابراین برای ذخیره سازی همه داده های دنیا به حدود 20 میلیارد PC نیاز است. در گذشته پروسه آشکارسازی ژنهای بشر تقریباً 10 سال وقت میگرفت ، هم اکنون بیشتر از یک هفته نمیشود. داده های چند رسانه ای وزن بزرگی در ترافیک اینترنت دارند و انتظار میرود به %70 در سال 2013 افزایش یابد. فقط google بیش از یک میلیون سرور در دور جهان دارد. 6 میلیارد اشتراک موبایل در دنیا وجود دارد و هر روز 10 میلیارد متن پیام (message) ارسال میشود.
در سال 2020 ، بیش از 50 میلیارد دستگاه به شبکه ها و اینترنت متصل خواهند بود.
در سال 2012 مواجهه بشر با big data به عنوان یک پروژه جهانی انجام شد با مرکزیت مجموعه ای بلادرنگ که مقدار بزرگی از داده ها را نمایش میدهد و تحلیل میکند. بر اساس این پروژه خیلی آمارها نتیجه گرفته شد
. Facebook ، نهصد و نود و پنج میلیون حساب کاربری فعال ماهانه با 70 زبان دارد ، 140 میلیارد تصویر آپلود شده است ، 125 میلیارد اتصالات دوستها و روزانه 30 میلیارد قطعه های با محتوا و 2.7 میلیارد like و comment ارسال میشود. هر دقیقه 48 ساعت ویدئو آپلود میشود و هر روز 4 میلیارد view در YouTube اجرا میشود.
Google خدمات بسیاری را پشتیبانی میکند از جمله 7.2 میلیارد page را هر روز مونیتور میکند و همچنین 20 پتا بایت (10 به توان 15 بایت) داده را روزانه به 66 زبان ترجمه میکند. یک میلیارد Tweet هر 72 ساعت از بیشتر از 140 میلیون کاربر فعال در Twitter داریم. 571 وبسایت جدید در هر دقیقه ساخته میشود. در حدود دهه بعد ، تعداد اطلاعات 50 برابر افزایش پیدا خواهد کرد اما تعداد متخصصان تکنولوژی اطلاعات که همه آن اطلاعات را کنترل میکنند ، 1.5 برابر افزایش پیدا خواهد کرد.
نمونه های واقعاً در دسترس از داده های حجیم عبارتند از : در ستاره شناسی ، علوم جوی ، ژنومیک(علم تجزیه وتحلیل داده های ژنتیکی) ، بیوژئوشیمی (شیمی زیستی جغرافیایی) ، علوم و تحقیقات زیستی ، دولت ، حوادث طبیعی ، منابع مدیریت ، بخش خصوصی ، مراقبت نظامی ، خدمات مالی ، جزئیات ، شبکه های اجتماعی ، وبلاگها ، متون ، اسناد ، عکاسی ، صوت ، ویدئو ، جریان کلیک کردن ، جستجو ، اندیس گذاری ، سوابق جزئیات تماس ، اطلاعات اعتباری ، شناسایی فرکانس رادیویی(RFID) ، تلفنهای همراه ، شبکه های حسگر و ارتباطات از راه دور. سازمانها در هر صنعتی که دارای داده های حجیم هستند .
Web همچنین نوعی از فرصت ها را برای داده های حجیم فراهم میکند. به عنوان مثال ، تحلیل شبکه های اجتماعی جهت درک هوش کاربر برای تبلیغات هوشمندتر ، کمپینهای بازاریابی و برنامه ریزی ظرفیت ، رفتار مشتری و الگوهای خرید و همچنین تجزیه و تحلیل احساسات. بر اساس این استنتاجها، شرکتها محتوای خود را و تدبیر توصیه خود را بهینه سازی میکنند. برخی از شرکتها نظیر گوگل و آمازون، مقالات مربوط به کار خود را چاپ میکنند.
با الهام از نوشته های چاپ شده ، توسعه دهندگان تکنولوژی های مشابهی نظیر نرم افزارهای open source از قبیل Lucene ، Solr ، Hadoop و HBase را توسعه دادند.
[1] RFID مخفف سه واژه Radio Frequency Identification به معنای “تشخیص با استفاده از فرکانس رادیویی” است
توجه:
- برای دانلود فایل word کامل ترجمه از گزینه افزودن به سبد خرید بالا استفاده فرمایید.
- لینک دانلود فایل بلافاصله پس از خرید بصورت اتوماتیک برای شما ایمیل می گردد.
به منظور سفارش تحقیق مرتبط با رشته تخصصی خود بر روی کلید زیر کلیک نمایید.
سفارش تحقیق







دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.