توضیحات
تحقیق خوشه بندی توزیع شده دادههای بزرگ در Hadoop با زبان R
چکیده
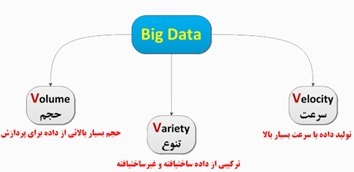
با توجه به خواص دادههای بزرگ همانند حجم، سرعت انتشار، تنوع، مقدار و پیچیدگی باید روشی جهت تجزیهوتحلیل و پردازش آنها انتخاب شود که ازنظر سرعت و دقت بهینه باشد. همچنین بستر انتخابی باید قابلیت پردازش حجم زیادی از دادهها بهصورت مناسب را داشته باشد. یکی از روشهای کاوش، استخراج دانش و تجزیهوتحلیل از دادههای بزرگ، روش خوشهبندی است. استفاده از نگاشت کاهش بهعنوان یکلایه ارتباطی و هماهنگکننده فعالیتهای بین چندین گره و یک مدل برنامهنویسی توزیع میباشد که بدین منظور از هادوپ به عنوان یک نمونه پیادهسازی شده معروف بر اساس روش نگاشت کاهش استفاده میشود.
در این تحقیق به بررسی خوشهبندی توزیعشده دادههای بزرگ (عظیم) با استفاده از هادوپ و R پرداخته میشود. بدین منظور، ابتدا مفهوم دادههای بزرگ و خوشهبندی دادههای بزرگ بر اساس نگاشت کاهش، بیان میشود. سپس هادوپ و خوشهبندی توزیعشده با استفاده از هادوپ و R بررسی میشود.
کلمات کلیدی: دادهکاوی، دادههای بزرگ، نگاشت کاهش، زبان برنامهنویسی R
بیان مسئله
امروزه با رشد فزاینده دادهها، استفاده از سیستمهای اطلاعات جغرافیایی فرماندهی و کنترل برای تصمیمگیری فرماندهان، کاربران و سازمانها اجتنابناپذیر بوده و بهبود ذخیره و بازیابی آنها، چالشی بزرگ به شمار میآید. ازاینرو یکی از حوزههای فعالیت محققان و پژوهشگران علوم کامپیوتر درزمینه دادههای بزرگ می باشد. دادههای بزرگ به دادههایی اطلاق میشود که به علت زیاد بودن مقدار آنها، نتوان با استفاده از روشهای سنتی تجزیهوتحلیل و پردازش شوند. به علت تولید حجم بسیار زیادی از دادهها در دنیای مجازی، پردازش و تحلیل دادههای بزرگ یکی از چالشهای اصلی محسوب میگردد.
مدل برنامهنویسی توزیعی نگاشت کاهش یک چارچوب برنامهنویسی برای محاسبات توزیعی میباشد که توسط گوگل ارائهشده، این مدل با استفاده از روش تقسیم و غلبه، مشکل حجم دادههای بزرگ تا حدی با شکستن داده به واحدهای کوچک و پردازش موازی آنها، حل میکند. ایده اصلی استفاده از نگاشت کاهش بهعنوان یکلایه ارتباطی و هماهنگکننده فعالیتهای بین چندین گره میباشد. از هادوپ برای تحلیل دادهها در مقیاس وسیع استفاده میشود. در شبیهسازیها دیدهشده که، کارایی هادوپ بهواسطه در نظر گرفتن برخی فرضیات بسیار محدودشده است.
…
فهرست مطالب تحقیق خوشه بندی توزیع شده دادههای بزرگ در Hadoop با زبان R
- فصل اول: مقدمه
- 1-1 بیان مسئله 2
- 2- 1 اهمیت و ضرورت تحقیق.. 2
- 3- 1 ساختارتحقیق 3
- فصل دوم: مرور مطالعاتی
- 1-2 مروری برروشهای خوشه بندی داده های بزرگ براساس نگاشت کاهش… 5
- 2-2 مقایسه روشهای خوشه بندی داده های بزرگ مبتنی برنگاشت کاهش 16
- فصل سوم: دادههای بزرگ مبتنی بر نگاشت کاهش
- 1-3 تعریف داده های بزرگ 19
- 2-3 ویژگیهای داده های بزرگ 20
- 3-3 چالش های داده های بزرگ.. 21
- 4-3 معماری داده های بزرگ 23
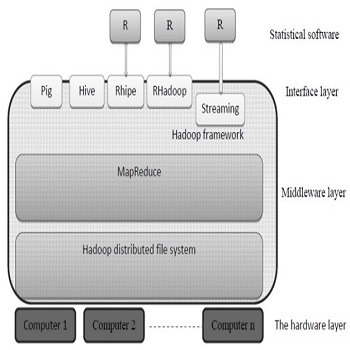
- 5-3 تعریف هادوپ 24
- 3-6 بررسی HDFS 27
- 3-7 تعریف نگاشت کاهش 28
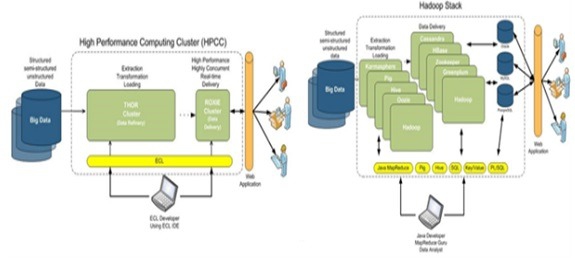
- 3-8 سیستم های HPCC 30
- 9-3 خوشه بندی داده های بزرگ.. 32
- فصل چهارم: خوشهبندی توزیعشده دادههای بزرگ در هادوپ و R
- 4-1 مقدمه 34
- 4-2 نحوه کارکرد نگاشت کاهش… 34
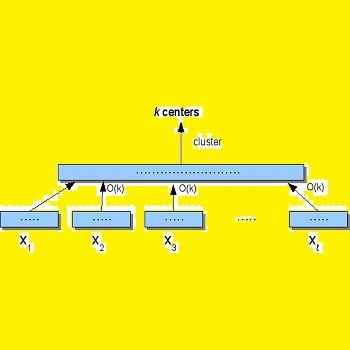
- 4-3 عملکرد P-PIC نگاشت کاهش 36
- 4-4 سیستم OACM 37
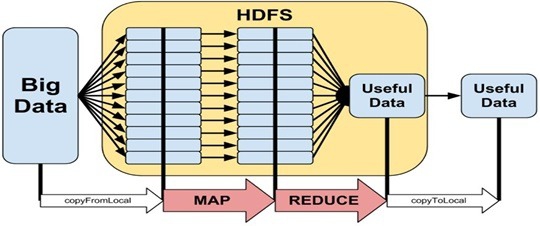
- 4-5 روندپردازش داده های عظیم با استفاده ازنگاشت کاهش هادوپ.. 38
- 4-6 خوشه بندی به روشK-MeansدرR. 40
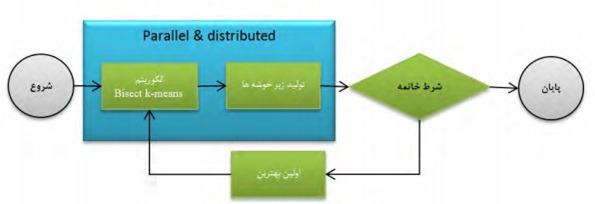
- 7-4 خوشه بندی means-k Bisectتوزیع شده درداده های بزرگ.. 43
- فصل پنجم: نتیجهگیری
- 5-1 نتیجه گیری 47
- منابع 48
منابع تحقیق خوشه بندی توزیع شده دادههای بزرگ در Hadoop با زبان R
[1] Yang, J., & Li, X. (2013, October). Map-Reduce based method for big data semantic clustering. In Systems, Man, and Cybernetics (SMC), 2013 IEEE International Conference on (pp. 2814-2819). IEEE. [2] Fahad, A., Alshatri, N., Tari, Z., Alamri, A., Khalil, I., Zomaya, A. Y., … & Bouras, A. (2014). A survey of clustering algorithms for big data: Taxonomy and empirical analysis. IEEE transactions on emerging topics in computing, 2(3), 267-279. [3] Zhao, W., Ma, H., & He, Q. (2009, December). Parallel k-means clustering based on Map-Reduce. In IEEE International Conference on Cloud Computing (pp. 674-679). Springer Berlin Heidelberg. [4]El-Sonbaty, Y., Ismail, M. A., & Farouk, M. (2004, November). An efficient density based clustering algorithm for large databases. In Tools with Artificial Intelligence, 2004. ICTAI 2004. 16th IEEE International Conference on (pp. 673-677). IEEE. [5] Priyanka, P. (2014). An Efficient Algorithm for ClusteringData Using Map-Reduce Approach. International Journal of Computer Science and Mobile Computing, 3(5,). [6] Ngazimbi, M. (2009). Data clustering using Mapکاهش. Boise State University, 1-72. [7] Ferreira Cordeiro, R. L., Traina Junior, C., Machado Traina, A. J., López, J., Kang, U., & Faloutsos, C. (2011, August). Clustering very large multi-dimensional datasets with Map-Reduce. In Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 690-698). ACM. [8] Fries, S., Wels, S., & Seidl, T. (2014). Projected Clustering for Huge Data Sets in Map-Reduce. In EDBT (pp. 49-60). [9] Zhu, Y. T., Wang, F. Z., Shan, X. H., & Lv, X. Y. (2014, August). K-medoids clustering based on Map-Reduce and optimal search of medoids. In Computer Science & Education (ICCSE), 2014 9th International Conference on (pp. 573-577). IEEE. [10] Fan J, Han F, Liu H. Challenges of big data analysis. National science review. 2014 Jun 1;1(2):293-314. [11] Labrinidis A, Jagadish HV. Challenges and opportunities with big data. Proceedings of the VLDB Endowment. 2012 Aug 1;5(12):2032-3. [12]Uskenbаyevа R (2015). Integrаting of dаtа using the Hаdoop аnd R. Procedia Computer Science,56,2015,145 – 149. [13] Dittrich J, Quiané-Ruiz JA. Efficient big data processing in hadoop Map-Reduce. Proceedings of the VLDB Endowment. 2012 Aug 1;5(12):2014-5. [14] Li, B., & Chan, K. C. (2014, November). A fast big data collection system using Map-Reduce framework. In 2014 IEEE 3rd International Conference on Cloud Computing and Intelligence Systems (pp. 530-535). IEEE. [15] del Río, S., López, V., Benítez, J. M., & Herrera, F. (2014). On the use of Map-Reduce for imbalanced big data using Random Forest. Information Sciences, 285, 112-137. [16] Jayalatchumy, D., Thambidurai, P., & Vasumathi, A. A. (2014, February). Parallel Processing of Big Data Using Power Iteration Clustering over Mapکاهش. In Computing and Communication Technologies (WCCCT), 2014 World Congress on (pp. 176-178). IEEE. [17] Bello-Orgaz, G., Jung, J. J., & Camacho, D. (2016). Social big data: Recent achievements and new challenges. Information Fusion, 28, 45-59.توجه:
تحقیق خوشه بندی توزیع شده دادههای بزرگ در Hadoop با زبان R شامل یک فایل ورد 55 صفحه ای می باشد.
لینک دانلود فایل بلافاصله پس از خرید بصورت اتوماتیک برای شما ایمیل می گردد.
به منظور سفارش تحقیق مرتبط با رشته تخصصی خود بر روی کلید زیر کلیک نمایید.
سفارش تحقیق






دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.