توضیحات
عنوان فارسی: بررسی پردازش کلان داده ها با استفاده از نگاشت کاهش در هادوپ
- مقدمه
- بیان مسئله
- ضرورت و اهمیت تحقیق
- ساختار تحقیق
- فصل دوم کلان داده ها
- مقدمه
- ویژگی های کلان داده ها
- کاربردهای داده های عظیم
- چالش های داده های عظیم
- کشف دانش از داده های حجیم(KDD)
- تحلیل داده های عظیم
- فصل سوم چارچوب متن باز هادوپ
- مقدمه
- تعریف Hadoop
- بررسی HDFS
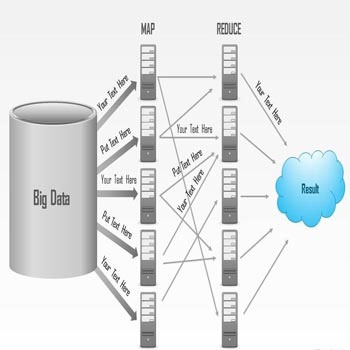
- تعریف MapReduce
- سیستم های HPCC
- فصل چهارم پیشینه تحقیق
- تعریف DBMS موازی های
- برنامه نویسی MapReduce
- فصل پنجم پردازش کلان داده با استفاده از MapReduce در هادوپ
- مقدمه
- نحوه کارکرد MapReduce
- عملکرد PPIC روی نگاشت کاهش
- سیستم OACM
- استفاده از MangoDB Apache در وب
- روند پردازش داده های عظیم با استفاده از MapReduce هادوپ
- فصل ششم نتیجه گیری
- نتیجه گیری
- منابع
چکیده
امروزه به واسطه ی افزایش استفاده از اینترنت و شبکه های اجتماعی حجم داده های موجود در فضای اینترنت بسیار افزایش داشته است به نحوی که هرگونه پردازش به روی آن از عهده ی کامپیوترهای معمولی خارج است. داده های تولیدشده از انواع منابع با حجم بسیار زیاد سرعت بالا و ساختمان داده متفاوت را کلان داده می نامند. امروزه کلان داده به عنوان یک منبع غنی و ارزشمند برای رنج گسترده ای از سازمانها به رسمیت شناخته شده است. نگاشتکاهش چارچوبی برای پردازش مجموعههای عظیمی از دادهها بر روی رایانهها است که بر روی موضوعی خاص فعالیت میکنند. نتیجه ی استفاده از این نرم افزارها صرفه جویی در وقت، هزینه و بالا بردن سرعت کارها و همچنین نزدیک شدن پردازش ها به حد ایده آل مورد نظر سازمان ها و شرکت های مختلف می باشد.
در این تحقیق ابتدا مفاهیم کلان داده و Hadoop بیان می شود. سپس به بررسی پردازش داده های کلان با استفاده از MapReduce در Hadoop پرداخته می شود.
کلمات کلیدی: داده های کلان، موازی سازی، Hadoop ، MapReduce.
فصل اول
مقدمه
1-1 بیان مسئله
امروزه چالش اصلی همه حوزه های شبکه و پایگاه داده، موضوع داده های عظیم (کلان داده) یا Big Data است. داده های عظیم مفهومی است که به تازگی مطرح شده و بطور کلی به افزایش حجم اطلاعات غیرساختارمند ویکپارچه درکنارذخیره سازی و پردازش آنها می پردازد. آنها بر روی پایگاه داده ها که به شکل حجیم رشد می کنند ، ذخیره میشوند و ضبط ، شکل دهی، ذخیره سازی، مدیریت، به اشتراک گذاری، تحلیل و نمایش آنها از طریق ابزارهای نوعی نرم افزار پایگاه داده ها ، دشوار میشود.
از این رو تحلیل های دقیق بر روی این داده های عظیم، منجر به تصمیم گیر یهای با اطمینان بیشتری شده و تصمیمات بهتر، می تواند معنای کارایی بیشتر عملیات، کاهش هزینه ها و کاهش ریسک ها باشد. به منظور پردازش و درهم شکستن مسائل داده های حجیم مختلط به بخشهای کاری کوچک و پردازش موازی آنها از MapReduce استفاده می شود. نگاشتکاهش چارچوبی برای پردازش مجموعههای عظیمی از دادهها بر روی رایانهها است که بر روی موضوعی خاص فعالیت میکنند. این مجموعه رویهم رفته به عنوان خوشه شناخته میشود. پردازش محاسباتی بر روی دادهایِ ذخیره شده درون سامانه فایل یا بر روی پایگاه داده قابل اجراست.
در ادامه این تحقیق به بررسی نقش MapReduce در پردازش داده های عظیم می پردازیم.
1-2 ضرورت و اهمیت تحقیق
با رشد روز افزون داده ها و نیاز به پردازش و تحلیل این داده ها، بکارگیری زیرساخت های داده های عظیم از اهمیت ویژه ای برخوردار شده است. مسئله واقعی این نیست که مقدار زیادی داده به دست آورید؛ این است که با آن چه می کنید. دیدگاه امیدوارانه این است که سازمان ها قادر به تحصیل داده از هر منبعی بوده، داده های مرتبط را تهیه کرده و آن را تحلیل کنند تا پاسخ سؤالاتی را بیابند که:
- کاهش هزینه ها،
- کاهش زمان،
- توسعه محصولات جدید و پیشنهادات جدید،
- تصمیم گیری هوشمندانه تر کسب وکار را مقدور می سازند.
برای مثال، با ترکیب داده عظیم و تحلیل های قوی، این امکان وجود دارد تا:
- علت های اصلی شکست ها، مسائل و نقوص را در لحظه تعیین کرد تا سالانه تا میلیاردها دلار صرفه جویی کرد.
- مسیر وسیله های حمل بسته های تحویلی را زمانی که هنوز در جاده هستند، بهینه کرد.
- در چند دقیقه تمام سبد ریسک را دوباره حساب کرد.
- سریعاً مشتریانی که بیشترین اهمیت را دارند، شناسایی کرد.
از آنجایی که برجسته ترین مزیت MapReduce مقیاس پذیری آسان پردازش داده ها روی چندین گره محاسباتی است، در نتیجه برای به دست آوردن نتایج فوق کارآمد است. از طرف دیگر، برنامه های MapReduce ذاتا موازی هستن، بنابراین آنالیز مجموعه داده های عظیم را به تعداد ماشین های کافی و در دسترس قرار می دهد. این الگوی دو مرحله ای در بسیاری از برنامه ها دیده می شود و تقریبا به یک چارچوب اساسی تبدیل شده است.
1-3 ساختار تحقیق
در فصل دوم به بررسی و بیان ویژگی های کلان داده ها پرداخته می شود. در فصل سوم پیشینه تحقیق بیان می شود. در فصل چهارم، هادوپ و نگاشت کاهش مورد بررسی قرار می گیرد. در فصل پنجم، پردازش کلان داده ها با استفاده از نگاشت کاهش در هادوپ بررسی می شود. نهایتا، در فصل ششم نتیجه گیری بیان می شود.
توجه:
- برای دانلود فایل word کامل ترجمه از گزینه افزودن به سبد خرید بالا استفاده فرمایید.
- لینک دانلود فایل بلافاصله پس از خرید بصورت اتوماتیک برای شما ایمیل می گردد.
به منظور سفارش تحقیق مرتبط با رشته تخصصی خود بر روی کلید زیر کلیک نمایید.
سفارش تحقیق







دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.