توضیحات
عنوان فارسی: پیش بینی نقص نرم افزار با استفاده از سیستم استنتاج عصبی فازی تطبیقی
عنوان انگلیسی مقاله ترجمه شده:
Software Defect Prediction using Adaptive Neuro Fuzzy Inference System
چکیده
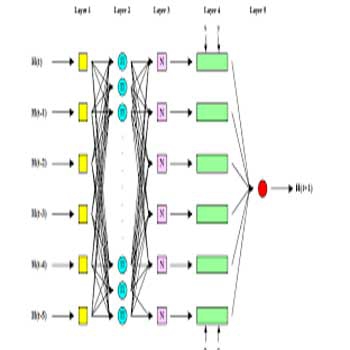
پیش بینی نقص نرم افزار در فرآیند توسعه نرم افزار یک چالش بزرگ برای کاهش هزینه های به کارگیری (پیاده سازی) نرم افزار است. پیش بینی ماژول ناقص مستعد در صنعت نرم افزار به میزان زیادی هزینه های توسعه نرم افزار را کاهش می دهد. بیشتر محققین از داده های مختلفی با به بکار گیری تکنیک هایی مثل آبادوست، شبکه عصبی، جنگل تصادفی و ماشین های بردار پشتیبانی برای مجموعه های داده ی پیش بینی نقص نرم افزار، گرفته شده از مخازن ناسا، استفاده کردند. این مجموعه داده ها در طبیعت نامتوازن هستند. در این مقاله نقوص نرم افزار با استفاده از سیستم استنتاج عصبی فازی تطبیقیANFIS پیش بینی شده است. سیستم استنتاج فازیFIS با استفاده از خوشه بندی کاهشی نتیجه شده و پس از آن با قوانین یادگیری ترکیبی فراگیری شده است. عملکرد رده بندی بر اساس مقادیر AuC (سطح زیر منحنی) برای این مجموعه داده های نامتوازن اندازه گیری می شود. ما نتایج ANFIS را با شبکه های عصبی حساس به هزینه مقایسه کردیم. منحنی مشخصه عملکرد سیستم ( منحنی عملیاتی دریافت کننده) در بخش نتایج حاصل و ارائه شده است. مقادیر منحنی عملیاتی دریافت کننده ی ANFIS در مقایسه با شبکه های عصبی حساس به هزینه رضایت بخش بوده است.
کلمات کلیدی: سیستم استنتاج عصبی فازی تطبیقی، مشخصه عملکرد سیستم، پیش بینی نقص نرم افزار، خوشه بندی کاهشی، یادگیری ترکیبی
مقدمه
در فرآیند توسعه نرم افزار، پیش بینی نقوص نرم افزار یک نقش اساسی ایفا می کند. پیش بینی یک نقص نرم افزار به صورت پیش رفته، هزینه توسعه نرم افزار را کاهش داده و کیفیت تولید نرم افزار را افزایش می دهد. ترجمه مقالات
۱-مدل براورد نقص ومعیار (متریک) ساده: به قول آکیاما، تعداد نقوص به معیار (متریک) نرم افزار، خط های برنامه LOC بستگی دارد. او یک معادله تعداد نقوص را به دست آورد. اما LOC برای به دست آوردن پیچیدگی نرم افزار کافی نیست.
۲-مدل های برازش و معیارهای پیچیدگی: در ۱۹۷۶، مک کوب معیارهای سیکلومتریک برای اندازه گیری پیچیدگی نرم افزار به دست آورد. پیچیدگی های سیکلومتریک یک برنامه که E تعداد لبه ها، V تعداد راس هاست. در ۱۹۷۷، هالستد اندازه گیری های پیچیدگی هالستد را معرفی کرد که پیاده سازی الگوریتم ها را در زبان های مختلف منعکس می کند. او مشاهده کرد که تعداد نقوص به تلاش بستگی دارد که به نوبه خود به سختی و حجم بستگی دارد. نقوص . اما محدود سازی این مدل این است که این فقط با داده های شناخته شده سازگار است و برای داده های جدید معتبر نیست.
۳-مدل های رگرسیونی: مطالعه تجربی شن و همکارانش نشان داد که مدل رگرسیون خطی در مدل های جدید واقعی می تواند معتبر باشد. او میانگین مقدار خطای نسبی MRE بین مقدار واقعی و تعداد پیش، خوشه بندی کاهشی بینی شده ی نقوص به عنوان 0.48 را به دست آورد. منسون و همکاران با استفاده از رگرسیون لجستیک با معیارهای پیچیدگی هالستد و سیکلومتریک، تحلیل های افتراقی اعمال کردند و دقت ۹۲ درصد به دست آوردند.
۴-مدل پیش بینی سر وقت Just in time: یک مطالعه تجربی بزرگ مقیاس در مورد کیفیت Just in time دقت ۶۸ درصد، یادآوری ۶۴ درصد روی ۱۱ متن (منبع) باز و پروژه های تجاری تضمین می شود.
۵-مدل های کاربردی: چیدامبر و کمرر معیارهای CK که برای پیش بینی نقص نرم افزار شئ گرا هستند، معرفی کردند. معیارها روش های وزنی در هر رده WMC ، عمق درخت وراثت DIT ، تعداد فرزندان NOC ، جفت شدگی بین اشیا و پاسخ برای یک رده RFC هستند.
توجه:
- برای دانلود فایل word کامل ترجمه از گزینه افزودن به سبد خرید بالا استفاده فرمایید.
- لینک دانلود فایل بلافاصله پس از خرید بصورت اتوماتیک برای شما ایمیل می گردد.
به منظور سفارش ترجمه تخصصی مقالات خود بر روی کلید زیر کلیک نمایید.
سفارش ترجمه مقاله









نقد و بررسیها
هنوز بررسیای ثبت نشده است.