
توضیحات
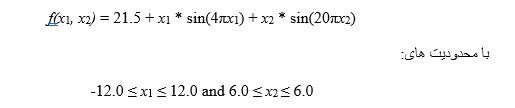
شبه کد الگوریتم ژنتیک پیاده سازی شده :
- تنظیم پارامترها (برای هر تست از الگوریتم ژنتیک به صورت جداگانه پارامترها معرفی می شود)
- تشکیل جمعیت اولیه برابر بعد مسئله و به تعداد دلخواه به صورت تصادفی در بازه تغییرات متغیر. سپس محاسبه مقدار برازندگی هر عضو (تابع برازندگی یک تابع دو بعدی x1 و x2 است که در مسئله مقدار ماکسیمم آن خواسته شده است که در این موارد می توان با توجه به ماهیت الگوریتم های بهینه سازی که غالبا کمینه ساز هستند تابع را معکوس کرد و کمینه آن را محاسبه کرد که در واقع همان بیشینه تابع اصلی است و در انتها نتیجه بهترین برازندگی را نیز معکوس کرد تا خواسته مسئله کاملا برآورده شود مطابق فرمول زیر)
![]()
- محاسبه میانگین جواب ها و بهترین جواب در میان تمامی جواب ها با مرتب سازی صعودی جواب ها (BestVariable, BestFunction)
- حلقه به تعداد تکرار تنظیم شده
- بروز رسانی میانگین جواب ها و بهترین جواب در ابتدای حلقه (می توان این کار را در انتهای حلقه نیز انجام داد ولی این روش هم مرسوم است و فقط بعد از پایان حلقه نیز باید مجددا این بروز رسانی را انجام داد)
- انتخاب ژن های پدر به صورت تصادفی و بر اساس انتخاب چرخ رولت با محاسبه احتمال تجمعی عناصر و سپس انجام عملیات ترکیب (تک نقطه ای single_point، دو نقطه ای two_pointو یکسان uniform) و عملیات جهش و تولید فرزندان از پدرهای انتخاب شده و سپس ترکیب پدرها و فرزندان
- محاسبه برازندگی جمعیت جدید و مرتب سازی آنها به ترتیب صعودی و سپس حذف جمعیت های اضافی برابر تعداد جمعیت اولیه
- رفتن به گام 4 تا زمان پایان شرط حلقه
- بروز رسانی میانگین جواب ها و بهترین جواب در انتهای حلقه و چاپ و نمایش خواسته های مسئله (نمودار های میانگین و بهترین جواب ها، پاسخ نهایی، مقادیر میانگین و انحراف استادارد مقادیر برازندگی)
- این پروژه آموزشی دارای 2 کد مختلف و جداگانه می باشد که در هر یک از راه حل های مختلف استفاده شده است.
تست شماره 1 الگوریتم ژنتیک
پارامترهای الگوریتم ژنتیک :
|
تعداد جمعیت اولیه (pop_s) = 1000 |
تعداد تکرار (Iterate) = 1000 |
|
مرز متغیرها (bound) = [[6,6-],[12,12-]] |
بعد مسئله (dim) = 2 |
|
احتمال عملیات جهش (prob_mu) = 0.0 |
احتمال عملیات ترکیب (prob_cross) = 0.7 |
|
نوع عملیات جهش (c_type) = one_point |
احتمال تعداد عناصر کاندید جهش (elit_ratio)=0.01 |
تست شماره 2 الگوریتم ژنتیک
پارامترهای الگوریتم ژنتیک :
|
تعداد جمعیت اولیه (pop_s) = 1000 |
تعداد تکرار (Iterate) = 1000 |
|
مرز متغیرها (bound) = [[6,6-],[12,12-]] |
بعد مسئله (dim) = 2 |
|
احتمال عملیات جهش (prob_mu) = 0.0 |
احتمال عملیات ترکیب (prob_cross) = 0.7 |
|
نوع عملیات جهش (c_type) = two_point |
احتمال تعداد عناصر کاندید جهش (elit_ratio)=0.01 |
تست شماره 3 الگوریتم ژنتیک
پارامترهای الگوریتم ژنتیک :
|
تعداد جمعیت اولیه (pop_s) = 1000 |
تعداد تکرار (Iterate) = 1000 |
|
مرز متغیرها (bound) = [[6,6-],[12,12-]] |
بعد مسئله (dim) = 2 |
|
احتمال عملیات جهش (prob_mu) = 0.0 |
احتمال عملیات ترکیب (prob_cross) = 0.7 |
|
نوع عملیات جهش (c_type) = uniform |
احتمال تعداد عناصر کاندید جهش (elit_ratio)=0.01 |

تست شماره 4 الگوریتم ژنتیک
پارامترهای الگوریتم ژنتیک :
|
تعداد جمعیت اولیه (pop_s) = 1000 |
تعداد تکرار (Iterate) = 1000 |
|
مرز متغیرها (bound) = [[6,6-],[12,12-]] |
بعد مسئله (dim) = 2 |
|
احتمال عملیات جهش (prob_mu) = 0.5 |
احتمال عملیات ترکیب (prob_cross) = 0.01 |
|
نوع عملیات جهش (c_type) = uniform |
احتمال تعداد عناصر کاندید جهش (elit_ratio)=0.01 |
به دلیل عدم خطا در کدها مقدار احتمال ترکیب نزدیک به صفر در نظر گرفته شده است نه خود صفر
تست شماره 5 الگوریتم ژنتیک
پارامترهای الگوریتم ژنتیک :
|
تعداد جمعیت اولیه (pop_s) = 1000 |
تعداد تکرار (Iterate) = 1000 |
|
مرز متغیرها (bound) = [[6,6-],[12,12-]] |
بعد مسئله (dim) = 2 |
|
احتمال عملیات جهش (prob_mu) = 0.3 |
احتمال عملیات ترکیب (prob_cross) = 0.7 |
|
نوع عملیات جهش (c_type) = uniform |
احتمال تعداد عناصر کاندید جهش (elit_ratio)=0.01 |
مقایسه
|
بالاترین مقدار تابع در 10 بار اجرا |
میانگین بالاترین مقدار تابع در 10 بار اجرا |
درصد عملیات جهش |
نوع عملیات ترکیب |
درصد عملیات ترکیب |
شماره تست |
|
37.06 |
35.46 |
00 |
تک نقطه ای |
70 |
1 |
|
37.12 |
35.48 |
00 |
دو نقطه ای |
70 |
2 |
|
37.74 |
35.49 |
00 |
توزیع یکسان |
70 |
3 |
|
39.04 |
38.77 |
50 |
توزیع یکسان |
00 |
4 |
|
39.05 |
38.86 |
30 |
توزیع یکسان |
70 |
5 |
1- تست های شماره 1 تا 3 تنها ا عملیات ترکیب استفاده می کند که به سرعت در نقاط بهینه محلی گیر می افتد و توانایی اکتشاف ندارند. در بین آنها عملیات ترکیب با توزیع یکسان عملکرد بهتری دارد.
2- تست شماره 4 تنها از عملیات جهش استفاده می کند و عملکرد آن در جستجو و اکتشاف بهبود پیدا کرده و در نقاط بهینه محلی کمتر گیر میکند اما هنوز قابل بهبود است
3- تست شماره 5 از هر دو نوع عملیات ترکیب و جهش استفاده می کند و توانایی بسیار خوبی در رسیدن به بهترین جواب نهایی (Global Best) از خود نشان داده است
پروژه آموزشی پیاده سازی یک الگوریتم ژنتیک شخصی برای حل مساله با پایتون توسط کارشناسان گروه ۱.۲.۳ پروژه پیاده سازی گردیده.
- فایلهای پروژه به صورت کامل پس از خرید فایل بلافاصله در اختیار شما قرار خواهد گرفت.
-
سفارش پروژه پایتون
درصورتیکه این پروژه دقیقا مطابق خواسته شما نمی باشد، با کلیک بر روی کلید زیر پروژه دلخواه خود را سفارش دهید.








دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.