
توضیحات
تحقیق روش های سنجش کیفیت داده در پایگاه داده ها
چکیده:
یکی از مسائل پیچیده در پایگاه داده که دارای جنبه های زیادی است کیفیت داده نام دارد. در تحقیق های زیادی که در این زمینه انجام شده است هر تحقیق به یک جنبه از کیفیت داده ها پرداخته است و هر تحقیق نیز برای یک کاربرد خاص است[1].
اینکه هر تحقیق یک جنبه را بیان میکند و برای یک کاربرد در نظر گرفته شده است به دلیل پیچیدگی کار است. برای کیفیت داده تعاریف زیادی در نظر گرفته شده است که تعدادی از آنها عبارتند از[1]:
“داده ای که نیازهای کاربر خود را برطرف کند کیفیت دارد.” همانطور که از تعریف ذکر شده مشخص است کیفیت داده با کاربرد تغییر میکند.
تعریف دیگر این است که:”داده ای که بتواند کارهای تصمیم گیری و برنامه ریزی کاربر را انجام دهد داده ای با کیفیت است.”
نکته ای که در این موضوع وجود دارد این است که کیفیت داده کاملا قابل سنجش و اندازه گیری است[1].
مقدمه:
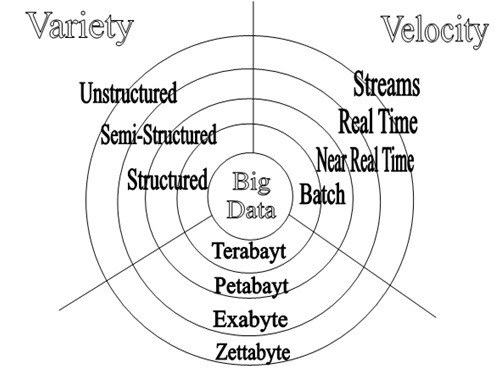
داده های بزرگ یا بیگ دیتا[1] به مجموعه ای از داده ها گفته میشود که اندازه آنها در اندازه ای نیست که با پایگاه داده معمولی بتوان آنها را مدریت کرد و یا الگوریتم های معمولی بر روی انها کارا نیست.
بیان مسئله:
دلیل پیشرفت روزافزون داده های حجیم و تحقیقات فراوان بر روی آنها این است که داده های زیادی در شرکت ها وجود دارد که استخراج داده های با کیفیت باعث به وجود آمدن فواید زیادی برای شرکت ها میشود و برای همین آنها در رقابت های سازمانی میتوانند از دیگر شرکت ها پیشی بگیرند.
با این رشد انفجاری در داده های ذخیره شده، نیاز به روشهایی است که اصطلاحا به کشف داده های مفید بپردازند یعنی داده های اضافی و کم اهمیت و یا دارای نویز را حذف کنند.[2]
در تحقیقات پیشین ﮐﯿﻔﯿﺖ داده ﺑﻌﻨﻮان ﻣﺠﻤﻮﻋﻪ اي از ﺻﻔﺎت اراﺋﻪ ﺷﺪه ﺑﻮد .اﯾﻨﮕﻮﻧﻪ اراﺋﻪ ﻣﻔﯿﺪ اﺳﺖ زﯾﺮا ﮐﺎرﺑﺮان ﺳﯿﺴﺘﻢ اﻃﻼﻋﺎت را ﻗﺎدر ﻣﯽ ﮐﻨﺪ ﺟﻨﺒﻪ ﻫﺎي ﻣﺨﺘﻠﻒ ﺑﻬﺒﻮد ﮐﯿﻔﯿﺖ داده را ﺷﻨﺎﺳﺎﯾﯽ ﮐﻨﻨﺪ . ﺳﺎﯾﺮ ﯾﺎﻓﺘﻪ ﻫﺎ اﯾﻦ ﻣﺴﺎﻟﻪ را ﺗﺎﺋﯿﺪ ﻣﯽﮐﻨﺪ ﮐﻪ اراﺋﻪ ﭼﻨﺪ ﺑﻌﺪي ﺑﺮاي ﺗﺼﻤﯿﻢ ﮔﯿﺮﻧﺪﮔﺎن ﮐﺴﺐ و ﮐﺎر ﺑﺎ ﻧﺸﺎن دادن ﺟﻨﺒﻪ ﻫﺎي ﻣﺨﺘﻠﻒ ﮐﯿﻔﯿﺖ ﺑﻪ آﻧﻬﺎ ﻣﻔﯿﺪ اﺳﺖ [2].
ﺣﺠﻢ زﯾﺎد داده، ﻣﻨﺎﺑﻊ ﮔﺴﺘﺮده داده و ﮐﺎرﺑﺮان ﻣﺘﻔﺎوت وﯾﮋﮔﯽ ﻫﺎي ﺳﺎزﻣﺎﻧﻬﺎي ﮐﻨﻮﻧﯽ ﻫﺴﺘﻨﺪ .ﺗﮑﻨﻮﻟﻮژي ﻫﺎي ﺑﯽ ﺳﯿﻢ و ﻣﻮﺑﺎﯾﻞ ﺑﺮ اﯾﻦ ﺣﺠﻢ اﻓﺰوده اﻧﺪ، ﭼﺮاﮐﻪ ﺑﻪ ﻫﻤﻪ اﻃﻼﻋﺎت در ﻫﺮ زﻣﺎن دﺳﺘﺮﺳﯽ وﺟﻮد دارد. ﭼﻨﯿﻦ ﻣﺤﯿﻄﯽ ﺗﺼﻤﯿﻢ ﮔﯿﺮﻧﺪﮔﺎن را ﻣﺠﺒﻮر ﻣﯽ ﮐﻨﺪ ﺗﺎ ﻋﮑﺲ اﻟﻌﻤﻞ ﺳﺮﯾﻌﺘﺮي داﺷﺘﻪ ﺑﺎﺷﻨﺪ ﮐﻪ ﻻزﻣﻪ آن ﺗﺼﻤﯿﻢ ﮔﯿﺮي ﺷﺎﻣﻞ ﺗﺼﻤﯿﻤﺎت ﻋﻤﻠﯿﺎﺗﯽ و ﺣﯿﺎﺗﯽ ﻣﯽﺑﺎﺷﻨﺪ. پشتیبانی ﺗﺼﻤﯿﻢ در ﭼﻨﯿﻦ ﻣﺤﯿﻂ ﻫﺎﯾﯽ ﻧﯿﺎزﻣﻨﺪ ﻣﺪﯾﺮﯾﺖ ﮐﯿﻔﯿﺖ داده میباشد. ﯾﺎﻓﺘﻪ ﻫﺎي ﻣﺎ ﭼﻨﯿﻦ ﺣﺲ ﻣﺸﺘﺮﮐﯽ را اﻟﻘﺎء میﮐﻨﺪ ﮐﻪ ﻫﻨﮕﺎﻣﯽ ﮐﻪ ﮐﺎرﺑﺮ اﻧﺘﻈﺎر درﯾﺎﻓﺖ داده ﻫﺎي ورودي ﺑﺎ ﮐﯿﻔﯿﺖ اﺳﺖ،ﺗﺼﻤﯿﻢ ﮔﯿﺮي اﺛﺮﺑﺨﺶ و ﻧﺘﺎﯾﺞ ﺗﺼﻤﯿﻢ آﻧﻬﺎ ﺑﻬﺒﻮد میﯾﺎﺑﺪ .اﯾﻦ ﻣﺴﺎﻟﻪ ﻣﻌﻨﯽ ﻣﺸﺨﺼﯽ در ﻃﺮاﺣﯽ ﻣﺤﯿﻂ ﺗﻌﺎﻣﻞ ﮐﺎرﺑﺮ و اﻫﻤﯿﺖ اﻧﺘﻘﺎل ﮐﯿﻔﯿﺖ داده ﺑﻪ ﮐﺎرﺑﺮ ﻧﻬﺎﯾﯽ دارد. داﺷﺘﻦ ﺣﺲ ﮐﯿﻔﯿﺖ داده ﻫﺎ آﻧﻬﺎ را ﻗﺎدر ﺑﻪ ﺑﮑﺎرﮔﯿﺮي ﺑﻬﺘﺮ و ﻣﻮﺛﺮ ﺗﺮ از داده میﮐﻨﺪ [3].
…
فهرست مطالب تحقیق روش های سنجش کیفیت داده در پایگاه داده ها
- فصل اول: مقدمات و کلیات… 10
- 1-1-مقدمه: 10
- 1-2-بیان مسئله: 10
- 1-3-اهداف تحقیق: 11
- 1-4-اهمیت موضوع: 12
- 1-4-مباحث تحت پوشش سمینار: 12
- فصل دوم: کلیات و مرور پیشینه: 13
- 2-1-مقدمه: 13
- 2-2-تعریف پایگاه داده های بزرگ: 14
- شکل 2-1:پایگاه داده بزرگ… 15
- 2-3-امنیت در پایگاه داده های بزرگ: 17
- 2-4-اهمیت و کاربرد پایگاه داده های بزرگ: 20
- فناوری اطلاعات: 20
- اقتصاد و کسب وکار: 21
- بازاریابی و فروش: 21
- 2-6-تعریف کیفیت داده: 22
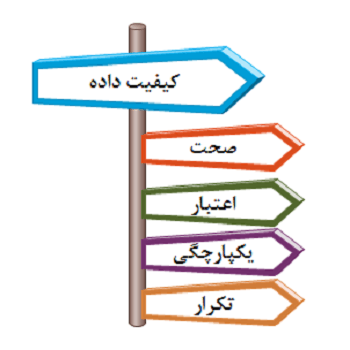
- 2-7-پارامترهای تاثیر گذار در ارزیابی کیفیت داده: 22
- 2-5-نتیجه گیری: 23
- فصل سوم: بررسی روش های انجام شده 24
- 3-1-مقدمه: 24
- 3-2-استفاده از الگوریتم ژنتیک برای بررسی کیفیت داده: 25
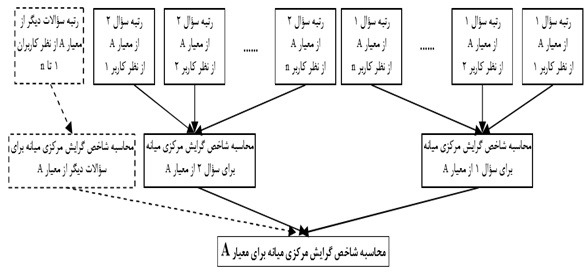
- 3-3–استفاده از روش تک معیاره برای تشخیص کیفیت داده ها: 26
- 3-4-استفاده از روش ترکیبی برای مدیریت کیفیت داده و حذف قوانین انجمنی حساس: 27
- 3-5- مدیریت کیفیت داده با استفاده از تحلیل داده های بزرگ: 29
- 3-6-ارزیابی کیفیت داده با استفاده از معیار قابل دسترس: 31
- 3-7-کیفیت داده بر اساس معیار فرمت خوب: 32
- فصل چهارم: نتیجه گیری و پیشنهادات… 34
- 4-1-مقدمه: 34
- لیست کیفیت داده ها 35
- 4-2-پیشنهاد: 36
- 4-3-نتیجه گیری: 37
- منابع: 39
منابع تحقیق روش های سنجش کیفیت داده در پایگاه داده ها
[1] G. Carlsson, Topological pattern recognition for point cloud data, Acta Numer.23 (2014) 289–368.
[2] IDC, Worldwide BIG gata Technology and Services 2012–2015 Forecast,
Vol. 1, 2012, IDC #233485.
[3] K. Kambatla, G. Kollias, V. Kumar, A. Grama, Trends in big data analytics,J. Parallel Distrib. Comput. 74 (2014) 2561–2573.
[4] – Nidhi Sharma,KAMALRAJ Anju Singh (2012) K-Partition Model for Mining Frequent Patterns in Large Databases. In International Journal on Computer Science and Engineering (IJCSE
[5] S.Y. Oudot, Persistence Theory: From Quiver Representations to Data Analysis, in: AMS Mathematical Surveys and M
[6] DIVYA BHATNAGAR,KAMALRAJ PARDASANI (2012) A MATRIX MODEL FOR MINING FREQUENT PATTERNS IN LARGE DATABASES.
In International Journal of Engineering Science and Technology (IJEST)
[7] – Nidhi Sharma,KAMALRAJ Anju Singh (2012) K-Partition Model for Mining Frequent Patterns in Large Databases. In International Journal on Computer Science and Engineering (IJCSEonographs, 2015.
[8] Nikunj H. Domadiya and Udai Pratap Rao,” A Hybrid Technique for Hiding Sensitive Association Rules and Maintaining Database Quality”, © Springer International Publishing Switzerland 2016
[9] Barna SahA,sivesh serivestivash,” Data Quality: The other Face of Big Data”, 978-1-4799-2555-1/14/$31.00 © 2014 IEEE
[10]sufal das,banana saha,” Data Quality Mining using Genetic Algorithm”,2013 ieee
[11] . Domadiya, N.H., Rao, U.P.: Hiding sensitive association rules to maintain privacy and data quality in database. In: 2013 IEEE 3rd International Conference on Advance Computing Conference (IACC), pp. 1306–1310 (2013)
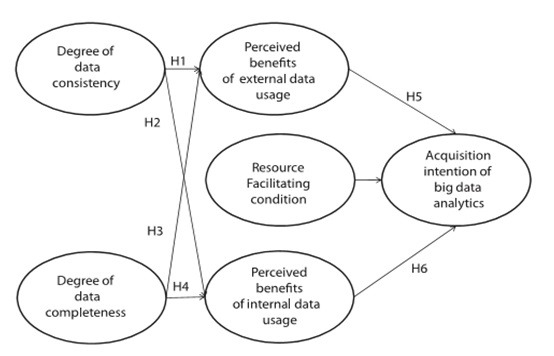
[12]ohbyung kwon, namyeon lee, ” data quality management, data usage experience and acquisition intention of big data analytics, international journal of information management 2014.
توجه:
تحقیق روش های سنجش کیفیت داده در پایگاه داده ها شامل یک فایل ورد 40 صفحه ای می باشد.
لینک دانلود فایل بلافاصله پس از خرید بصورت اتوماتیک برای شما ایمیل می گردد.
به منظور سفارش تحقیق مرتبط با رشته تخصصی خود بر روی کلید زیر کلیک نمایید.
سفارش تحقیق








نقد و بررسیها
هنوز بررسیای ثبت نشده است.