توضیحات
پروژه داده کاوی طبق دیتاست ارزیابی دانشجویان ترکیه با متلب
توضیح مسئله
در انجام این پروژه متلب قصد داریم تا چندین روش دسته بندی را روی یک دیتاست مورد ارزیابی قرار دهیم. دسته بندهای انتخابی ما عبارت اند از:
- شبکه عصبی
- ماشین بردار پشتیبان
- بیز ساده
- نزدیک ترین همسایگی
تفسیر داده ها
دادگانی که برای این تمرین انتخاب کردهایم مربوط به دیتاست ارزیابی دانشجویان ترکیه است. که اطلاعات آن در زیر موجود است.
|
Data Set Characteristics: |
Multivariate |
Number of Instances: |
1151 |
Area: |
Life |
|
Attribute Characteristics: |
Integer, Real |
Number of Attributes: |
20 |
Date Donated |
2014-11-03 |
|
Associated Tasks: |
Classification |
Missing Values? |
N/A |
Number of Web Hits: |
107023 |
مشخصات این دیتاست در شکل زیر آورده شده است. این دیتاست شامل 5820 نمونه است که هر نمونه 33 ویژگی دارد. مقادیر این دیتاست به صورت عدد طبیعی است. این دیتاست در سال 2013 جمع آوری شده است و تا کنون در حدود 57 هزار مقاله و تحقیق رفرنس داده شده است.
این دیتاست شامل 28 ویژگی اصلی و 5 ویژگی فرعی است. در اطلاعات این دیتاست ذکر نشده است که برچسب دیتاست کدام است. با اینحال ما یکی از ویژگی ها را به عنوان برچسب انتخاب میکنیم. این ویژگی np.repeat است که نشان دهنده تعداد دفعاتی است که دانشجو این درس را میگیرد. طبق مرجع [1] دیتاست را به دو کلاس تقسیم میکنیم. کلاس اول، به معنی این است که دانشجو یا این درس را نمیگیرد (مقدار ویژگی 0) یا فقط یکبار آن را میگیرد (مقدار ویژگی 1) . و اگر دانشجو بیش از یکبار این را بگیرد، در نتیجه مقدار نمونه در کلاس دوم قرار خواهد گرفت.
پردازش داده ها
در این قسمت داده ها را از فایل csv خوانده و ویژگی سوم که برچسب هست را جدا میکنیم. برچسب ها را طبق مرجع [1] در دو کلاس طبقه بندی میکنیم و برچسب های 1 و 2 به آن ها میدهیم. سپس داده های گمشده را با استفاده از درون یابی خطی پیدا میکنیم و دیتاست را اصلاح میکنیم. در پایان داده ها آماده دادن به دسته بند ها برای آموزش است.
مدلهای دسته بندی
شبکه عصبی
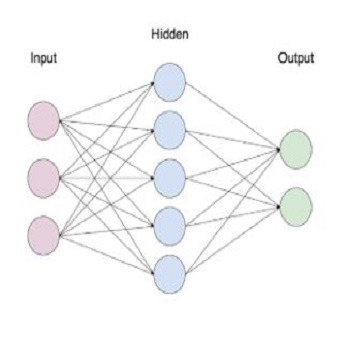
شبکه عصبی یک ساختار لایه ای است که متشکل از تعدادی نورون است. این نورونها توسط اتصالاتی به یکدیگر متصل شده اند. هدف شبکه عصبی پیدا کردن وزن های این اتصالات است به گونه ای که بهترین دقت دسته بندی را ارائه دهد. لایه ورودی به تعداد ویژگی هاست. لایه خروجی به تعداد کلاسها و لایه مخفی میتواند هر تعداد نورون داشته باشد.
ماشین بردار پشتیبان
روش SVM یا ماشین بردار پشتیبان، یک روش یادگیری خطی است که سعی در پیدا کردن یک خط (در ابعاد بالاتر، یک ابرصفحه) دارد تا بین داده ها جداسازی انجام دهد. اما میدانیم که برای جدا کردن داده ها میتوان بی نهایت خط پیدا کرد. اما ماشین بردار پشتیبان سعی میکند که بهینه ترین خط ممکن را پیدا کند. این خط جایی است دقیقا بین دو کلاس که بیشرین حاشیه را از داده های دو کلاس داشته باشد. سمت چپ شکل زیر دو خط جداساز غیربهینه را نشان میدهد. اما در سمت چپ بهینه ترین خط جداساز که توسط ماشین بردار پشتیبان بدست می آید را مشاهده میکنیم.
بیز ساده
یک روش یادگیری بسیار عملی روش بیز ساده است. در کاربردهایی نظیر دستهبندی متن و تشخیص پزشکی این روش کارایی قابل مقایسهای با شبکههای عصبی و درخت تصمیم دارد. ایده اصلی این روش به این صورت است که یک احتمال ثانویه را از ویژگیهای موجود در مسئله محاسبه کنیم با فرض اینکه هیچ ارتباطی بین ویژگیهای مسئله نباشد؛ یعنی فرض استقلال بین ویژگیهای مسئله. به خاطر چنین فرض عجیب و سادهانگارانهای که وجود دارد، این روش را روش بیز ساده یا احمقانه میگویند. با اینکه اسم این روش ساده نامیده شده است ولی در عمل کارایی خوبی دارد و توانسته در عملیاتهای دادهکاوی و یادگیری ماشین تا حد قابل قبولی خوب عمل کند.
نزدیک ترین همسایگی
روشی تنبل اما با دقت مناسب. منظور از تنبل بودن این روش این است که روش نزدیک ترین همسایگی هیچ آموزشی ندارد و برچسب داده های تست را با مقایسه بین نمونه تست و نمونه های آموزشی مشخص میکند. به این صورت که در اطراف نمونه تست یک بازه همسایگی در نظر میگیرد و با توجه به همسایه ها مشخص میکند که نمونه تست شبیه به کدام یک از همسایگی هاست. نمونه تست متعلق به کلاسی است که بیشترین همسایگی از آن کلاس را داشته باشد. برای محاسبه فاصله و شباهت بین داده از معیار فاصله اقلیدسی استفاده میشود. مقدار همسایگی میتواند در دقت نهایی دسته بندی مهم باشد.
نتایج پیاده سازی
بعد از اجرای پیاده سازی متلب، یک نمودار میله ای به صورت زیر به ما داده میشود.
نمودار بالا دقت دسته بندی را به ازای روش های مختلف دسته بندی به ما میدهد. همانگونه که مشخص است بدترین روش دسته بندی متعلق به بیز ساده با 68.8% است. بهترین دقت را شبکه عصبی با 83.74% داشته است. نکته جالب توجه این است که روش های ماشین بردار پشتیبان و شبکه عصبی با اختلاف زیادی از سایر روش ها ، دقت دسته بندی خوبی را ارائه داده اند که نشان از قدرت این روش ها دارد.
دلیل اینکه روش های شبکه عصبی و ماشین بردار پشتیبان دقت بیشتری دارند این است که این روش ها دسته بند خطی هستند و بر پایه ریاضیات و جداسازی خطی بنا شده اند. به همین دلیل از لحاظ بنیاد ریاضیاتی نسبت به سایر روش ها قوی تر هستند.
اما در بیز ساده یک فرض داریم که ویژگی های مسئله از یکدیگر مستقل هستند. این فرض با اینکه باعث ساده سازی میشود اما باعث دور ریختن اطلاعاتی از جمله وابستگی داده خواهد شد.
در نزدیک ترین همسایگی نیز هیچ آموزشی نداریم و داده های تست بر اساس شباهتی که به داده های آموزشی دارند دسته بندی میشوند و این شباهت با استفاده از معیار فاصله اقلیدسی به دست می آید.
پروژه شبیهسازی گیرنده و فرستنده و اکوالایزر کانال با متلب توسط کارشناسان گروه ۱.۲.۳ پروژه پیاده سازی گردیده و به تعداد محدودی قابل فروش می باشد.
- فایلهای پروژه به صورت کامل پس از خرید فایل بلافاصله در اختیار شما قرار خواهد گرفت.







نقد و بررسیها
هنوز بررسیای ثبت نشده است.