
توضیحات
عنوان فارسی: داده های عظیم
- فصل اول کلیات تحقیق
- بیان مسئله
- اهمیت و ضرورت مسئله
- ساختار تحقیق
- فصل دوم داده های عظیم
- مقدمه
- پیشینه تحقیق
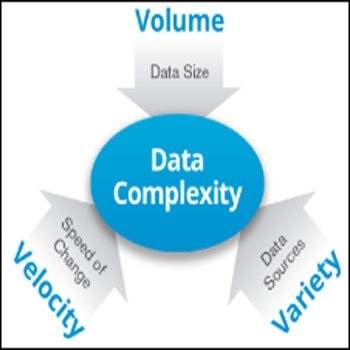
- ویژگی های داده های عظیم
- کاربردهای داده های عظیم
- تفاوت داده های عظیم و هوش تجاری
- معماری داده های عظیم
- تحلیل داده های عظیم
- فصل سوم چالش ها و تکنولوژی های داده های عظیم
- مقدمه
- چالش های داده های عظیم
- تکنولوژیها و تجهیزات مورد نیاز در داده های عظیم
- چالش های پیاده سازی تجزیه و تحلیل داده های عظیم
- اینترنت اشیا و داده های عظیم
- جمعآوری و ذخیرهسازی دادهها
- معماری و پروتکلهای اینترنت اشیا
- رایانش ابری و داده های عظیم
- سیتمهای (HPCC)high performance computing cluster
- کشف دانش از داده های حجیم(KDD)
- مهارت ها و عناوین شغلی در زمینه داده های عظیم
- مسائل حفظ حریم خصوصی و امنیت در داده های عظیم
- پیش بینی آینده داده های عظیم
- فصل چهارم نتیجه گیری
- نتیجه گیری
- منابع
چکیده
امروزه چالش اصلی همه حوزه های شبکه و پایگاه داده، موضوع داده های عظیم یا Big Data است. داده های عظیم مفهومی است که به تازگی مطرح شده و بطور کلی به افزایش حجم اطلاعات غیرساختارمند ویکپارچه درکنارذخیره سازی و پردازش آنها می پردازد. داده های عظیم اکنون چالش اصلی شبکه های گسترده و شرکت های بزرگ است. این داده ها از تراکنشهایonline ، email ها، ویدئوها، صوتها، کلیک کردن ها، log ها و ارسالها، درخواستهای جستجو، یادداشتهای درست، تعاملات شبکه های اجتماعی ، داده های علمی ، سنسورها و تلفنهای همراه و برنامه های کاربردی آنها تولید میشوند. آنها بر روی پایگاه داده ها که به شکل حجیم رشد میکنند ، ذخیره میشوند و ضبط ، شکل دهی، ذخیره سازی، مدیریت، به اشتراک گذاری، تحلیل و نمایش آنها از طریق ابزارهای نوعی نرم افزار پایگاه داده ها ، دشوار میشود.
از این رو تحلیل های دقیق بر روی این داده های عظیم، منجر به تصمیم گیر یهای با اطمینان بیشتری شده و تصمیمات بهتر، می تواند معنای کارایی بیشتر عملیات، کاهش هزینه ها و کاهش ریسک ها باشد. در این تحقیق، به بررسی داده های عظیم و چالش های این نوع داده ها می پردازیم.
کلمات کلیدی: داده های عظیم، رایانش ابری، اینترنت اشیا، تحلیل داده.
فصل اول
کلیات تحقیق
بیان مسئله
داده به طرز باور نکردنی ارزان و همه جا وجود دارد . ما در حال دیجیتال کردن محتویاتی می باشیم که در طی قرن ها ایجاد شده است و با حجم بسیار بالایی از اطلاعات با نوع های جدید نظیر لاگ های وب ، شبکه های اجتماعی، دستگاه های موبایل، سنسورها، تجهیزات اندازه گیری و تراکنش ها مواجه هستیم. به موازات این کار ، فناوری های جدیدی در حال ظهور است تا قادر به سازماندهی بهمن داده باشیم . ما هم اینک می توانیم الگوها و قواعدی را در داده ها و تمامی نوع ها شناسایی کنیم که به ما اجازه استفاده از دستاوردهای متعددی را در حوزه های مختلفی نظیر بهبود شرایط انسانی ، ایجاد ارزش اجتماعی و تجاری را می دهد.ظهور داده های عظیم یا Big Data این ظرفیت و پتانسیل را ایجاد کرده است که بتوانیم عمیق تر پدیده های محیط اطراف خود را از سیستم های فیزیکی و بیولوژیکی گرفته تا رفتارهای اقتصادی و اجتماعی بهتر شناسایی و تحلیل کرده و بر اساس آن بهترین تصمیمات را اتخاذ نماییم. Big data اصطلاحی است برای مجموعه داده های حجیم که بزرگ ، متنوع ، با ساختار پیچیده و با دشواریهایی برای ذخیره سازی ، تحلیل و تصویرسازی (نمایش) ، پردازشهای بیشتر یا نتایج میباشد. کلانداده معمولاً شامل مجموعه اطلاعاتی است که به طور معمول فراتر از حدی است که بتواند در ابزارهای تصویر، مدیریتی و فرایند اطلاعات در زمان قابل قابل تحمل که تمام میشود، استفاده شود. اندازه کلانداده به طور ثابت به مقدار هدف نزدیک میشود، از سال ۲۰۱۲ که در حد چند ترابایت بوده به پتا بایت رسیده است. کلانداده مجموعهای تکنیکها و تکنولوژیهایی است که که به فرم جدیدی از دستهبندی به منظور مشخص کردن ارزشهای پنهانی از پایگاه کلانداده که تغییر کرده، پیچیده شده و دارای مقیاس بالایی است، مورد نیاز میباشد. پروسه تحقیق بر روی داده های حجیم جهت آشکارسازی الگوهای مخفی و راز همبستگی ها ، تجزیه و تحلیل داده های عظیم نامیده میشود. این اطلاعات مفید برای سازمانها وشرکتها در جهت کسب بینش غنی تر و عمیق تر و موفقیت در رقابت کمک میکند. به همین دلیل اجراهای داده های عظیم نیاز دارند تا در صورت امکان ، تحلیل شوند و به طور دقیق اجرا شوند.
اهمیت و ضرورت مسئله
ازسال 1980 سرانه ذخیره سازی اطلاعات فنی جهان تقریبا هر40ماه یکباردوبرابر شده است ازسال 2012 هرروز 2.5 quintillion 2.5×10 18 بایت ازداده ها ایجادشده است تعیین اینکه چه سازمانی باید طرح های مربوط به داده های بزرگ را پیاده سازی کند خودچالشی بزرگ است. داده های بزرگ تاکتیک هایی است که نیازمند شکل جدیدی از یکپارچگی هستند تا بتوانند ارزش های بزرگی را که در مجموعه های بزرگ، وسیع، پیچیده و متنوع داده پنهان شده اند، آشکار سازند.
از این رو با رشد روز افزون داده ها و نیاز به بهره برداری و تحلیل از این داده ها، بکارگیری زیرساخت های داده های عظیم از اهمیت ویژه ای برخوردار شده است. مسئله واقعی این نیست که مقدار زیادی داده به دست آورید؛ این است که با آن چه می کنید. دیدگاه امیدوارانه این است که سازمان ها قادر به تحصیل داده از هر منبعی بوده، داده های مرتبط را تهیه کرده و آن را تحلیل کنند تا پاسخ سؤالاتی را بیابند که:
- کاهش هزینه ها،
- ) کاهش زمان،
- توسعه محصولات جدید و پیشنهادات جدید،
- تصمیم گیری هوشمندانه تر کسب وکار را مقدور می سازند.
برای مثال، با ترکیب داده عظیم و تحلیل های قوی، این امکان وجود دارد تا:
- علت های اصلی شکست ها، مسائل و نقوص را در لحظه تعیین کرد تا سالانه تا میلیاردها دلار صرفه جویی کرد.
- مسیر وسیله های حمل بسته های تحویلی را زمانی که هنوز در جاده هستند، بهینه کرد.
- در چند دقیقه تمام سبد ریسک را دوباره حساب کرد.
- سریعاً مشتریانی که بیشترین اهمیت را دارند، شناسایی کرد.
ساختار تحقیق
در ادامه تحقیق، در فصل دوم به معرفی و بیان معماری و ویژگی های داده های عظیم پرداخته می شود. در فصل سوم، چالش ها و تکنولوژی های مربوط به داده های عظیم مورد یررسی قرار می گیرند. نهایتا، در فصل چهارم نتیجه گیری بیان می شود.
فصل دوم
داده های عظیم
مقدمه
داده عظیم، به مجموعه داده هایی اطلاق می گردد که حجم و سرعت تولید آنها بیش از ظرفیت و امکانات بانک های اطلاعاتی مرسوم برای ضبط ، ذخیره سازی ، مدیریت و تحلیل داده است و نتوان آنها را با یک پردازشگر معمولی پردازش کرد.در واقع، عبارت داده عظیم مدتها است که برای اشاره به حجمهاي عظیمی از دادهها که توسط سازمانهای بزرگی مانند گوگل یا ناسا ذخیره و تحلیل ميشوند مورد استفاده قرار ميگیرد. اما به تازگي، این عبارت بیشتر برای اشاره به مجموعههای دادهاي بزرگی استفاده ميشود که به قدری بزرگ و حجیم هستند که با ابزارهای مدیریتی و پایگاههاي داده سنتي و معمولي قابل مدیریت نیستند. مشکلات اصلي در کار با این نوع دادهها مربوط به برداشت و جمعآوری، ذخیرهسازی، جستوجو، اشتراکگذاری، تحلیل و نمایش آنها است. این مبحث، به این دلیل هر روز جذابیت و مقبولیت بیشتری پیدا ميکند که با استفاده از تحلیل حجمهاي بیشتری از دادهها، ميتوان تحلیلهاي بهتر و پيشرفتهتري را برای مقاصد مختلف، از جمله مقاصد تجاری، پزشکی و امنیتی، انجام داد و نتایج مناسبتری را دریافتکرد[9]. بيشتر تحلیلهای مورد نیاز در پردازش دادههاي عظیم، توسط دانشمندان در علومی مانند هواشناسی، ژنتیک، شبیهسازیهاي پیچیده فیزیک، تحقیقات زیستشناسی و محیطی، جستوجوی اینترنت، تحلیلهاي اقتصادی و مالی و تجاری مورد استفاده قرار ميگیرد. حجم دادههاي ذخیرهشده در مجموعههاي دادهاي داده عظیم ، عموماً بهخاطر تولید و جمعآوری دادهها از مجموعه بزرگی از تجهیزات و ابزارهای مختلف مانند گوشیهاي موبایل، حسگرهای محیطی، لاگ نرمافزارهای مختلف، دوربینها، میکروفونها، دستگاههاي تشخیص RFID، شبکههاي حسگر بیسیم وغيره با سرعت خیرهکنندهاي در حال افزایش است. در این مقاله ضمن بررسی مفاهیم پایه ای در بزرگ داده، به بررسی راه حل های موجود برای مدیریت و بهره برداری از این نوع داده ها خواهیم پرداخت[7].
برای ایجاد یک دید مناسب در خصوص کلان داده و اهمیت آن، جامعه ای را تصور کنید که در آن جمعیت بطور نمایی در حال افزایش است، اما خدمات و زیرساخت های عمومی آن نتواند پاسخگوی رشد جمعیت باشد و از عهده مدیریت آن برآید. چنین شرایطی در حوزه داده در حال وقوع است. بنابراین نیازمند توسعه زیرساخت های فنی برای مدیریت داده و رشد آن در بخش هایی نظیر جمع آوری، ذخیره سازی، جستجو، به اشتراک گذاری و تحلیل می باشیم. دستیابی به این توانمندی معادل است با شرایطی که مثلا بتوانیم “هنگامی که با اطلاعات بیشتری در حوزه سلامت مواجه باشیم، با بازدهی بیشتری سلامت را ارتقا دهیم”، “در شرایطی که خطرات امنیتی افزایش پیدا میکند، سطح امنیت بیشتری را فراهم کنیم”، “وقتی که با رویدادهای بیشتری از نظر آب و هوایی مواجه باشیم، توان پیش بینی دقیقتر و بهتری بدست آوریم”، “در دنیایی با خودروهای بیشتر، آمار تصادفات و حوادث را کاهش دهیم”، “تعداد تراکنش های بانکی، بیمه و مالی افزایش پیدا کند، ولی تقلب کمتری را شاهد باشیم”، “با منابع طبیعی کمتر، به انرژی بیشتر و ارزانتری دسترسی داشته باشیم” و بسیاری موارد دیگر از این قبیل که اهمیت پنهان کلان داده را نشان می دهد.
پیشینه تحقیق
تحقیقات پنهانی و اطلاعات گروهی در کلانداده، در مارس ۲۰۱۴ در انجمن آمریکایی آموزش مهندسی نشان داده شده است. گوانتام سویچ در اداره کردن چالشهای کلانداده توسط علوم کامپیوتر MIT، کتابخانه هوش مصنوعی و و دکتر امیر اسمائیلور در گروه تحقیقی UNH هستند که خصوصیات کلیدی اطلاعات عظیم را به عنوان تشکلی گروههای که ارتباط داخلی دارند، بررسی کردند. آنها بر امنیت کلانداده و جهت گیری واقعی آن در اصرار ورزیردن بر انواع مختف اطلاعات در یک قابل پنهانی در اتصال عظیم، از طریق ایجاد تعاریف خام و مثالهای زمان واقعی در داخل تکنولوژی، تمرکز کردند. علاوه بر آن، آنها رهیافتی را برای شناسایی روشهای تجزیه کدها برای حرکت سمت سرعت بخشین تحقیقات در طول متنهای پنهان را پیش نهاد دادند که منجر به افزایش امنیت در کلانداده میشود.
در مارس ۲۰۱۲، کاخ سفید ابتکارات کلانداده ملی را انتشار داد که در دپارتمانهای فدرال و آژانسهای مأمور تشکیل شده است و بیش از ۲۰۰ میلیون دلار برای پروژههای تحقیقی کلانداده در نظر گرفته است.
این ابتکار شامل صندوق علمی ملی مربوط به تسریع در محاسبات است که دارای کمک ۱۰ میلیون دلاری در طول ۵ ساله آزمایش AMP در دانشگاه برکلی کالیفرنیا، بوده است. آزمایشگاه AMPL همچنین از DAEPA کمک نقدی دریافت میکند، و در طول دهها صنعت اسپانسر دارد و تا بر دامنه وسیعی از مشکلات مربوط به پیش بینی ترافیک ازدحام مربوط به مبارزه با سرطان، مقابله کند.
طرح ابتکاری کاخ سفید در مورد کلانداده همچنین شامل یک مأموریتی برای دپارتمان انرژی به منظور تهیه کردن ۲۵ میلیون دلار در صندوق در طول ۵ سال بود تا مؤسسه نظارت، تحلیل و مدیریت اطلاعات افزایش (SDVA) تأسیس شود، که توسط دپارتمان انرژی کتابخانه ملی برکلی لورانس، انجام شد. هدف مؤسسه SDAV جمعآوری کارشناسان از شش آزمایشگاه ملی و هفت دانشگاه، به منظور توسعه ابزارهای جدید برای کمک به مدیریت لمی و نظارت بر دیتا در سوپرکامپبوترهای دپارتمان میباشد.
ایالت ماساچوست آمریکا در می ۲۰۱۲ طرح ابتکاری کلانداده ماساچوست را بیان کرد که صندوقی را از دولت محلی و شرکتهای خصوصی تأسیس میکرد که هدف آن تنوع موسسات تحقیقی بود. مؤسسه فنی ماساچوست دارای علوم اینتل و مرکز فنی کلانداده در آزمایشگاه هوش مصنوعی و علم کامپیوتر MIT، ملحق شده با دولت، تعاونی و صندوق مؤسسه و فعالیتهای تحقیقی میباشد.
کمیسیون اروپا یک محکمه خصوصی انتشار کلانداده را در طول دوسال، از طریق چارچوب برنامه هفتم، به منظور مسولیت شرکتها، دانشگاهیان و دیگر سهام دارای در بحثهای مربوط به کلانداده، فراهم کرده است. هدف پروژه تعریف یک استراتژی به نحوی است که در تحقیق و ابتکارات، دارای اقدامات حمایتی کمیسیون اروپا در اجرای موفق اقتصاد کلانداده میباشد. خروجی این پروژه به عنوان ورودی در افق ۲۰۲۰، برنامه چارچوبی بعدی، استفاده میشود. دولت انگلیس در مارس۲۰۱۴ بیان کرد که پیدایش مؤسسه Alan Turing بعد از کامپیوترهای اولویت دارد و شکننده کد، بر روشهای جدید در جمعآوری و تحلیل مجموعههای کلانداده تمرکز خواهد کرد.
توجه:
- برای دانلود فایل word کامل ترجمه از گزینه افزودن به سبد خرید بالا استفاده فرمایید.
- لینک دانلود فایل بلافاصله پس از خرید بصورت اتوماتیک برای شما ایمیل می گردد.
به منظور سفارش تحقیق مرتبط با رشته تخصصی خود بر روی کلید زیر کلیک نمایید.
سفارش تحقیق






نقد و بررسیها
هنوز بررسیای ثبت نشده است.