توضیحات
شبیه سازی خوشه بندی داده های IRIS و PIMA توسط الگوریتم K-means با متلب
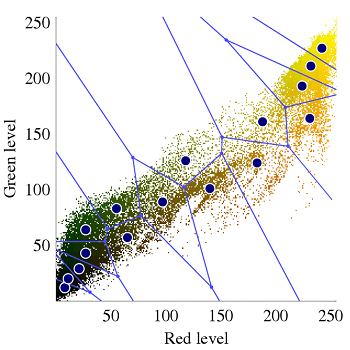
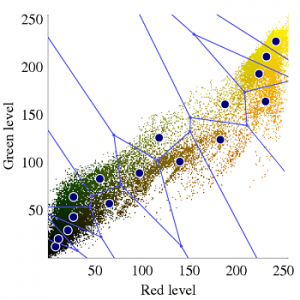
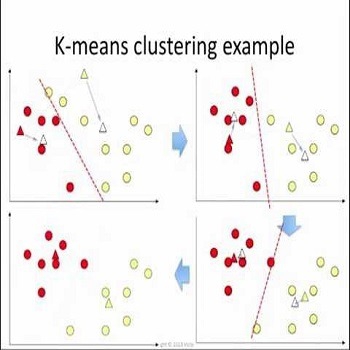
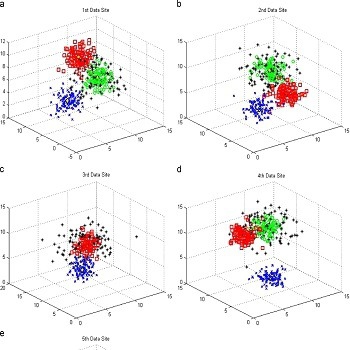
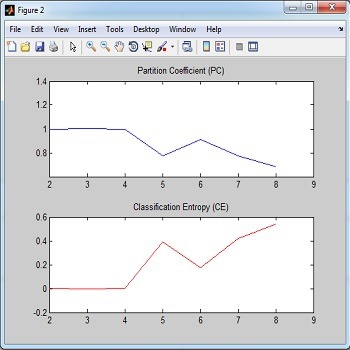
روش میانگین k در عین سادگی یک روش بسیار کاربردی و پایه چند روش دیگر مثل خوشه بندی فازی و Segment-wise distributional clustering Algorithm میباشد. روش کار به این صورت است که ابتدا به تعداد دلخواه نقاطی به عنوان مرکز خوشه در نظر گرفته میشود. سپس با بررسی هر داده، آن را به نزدیکترین مرکز خوشه نسبت میدهیم. پس از اتمام این کار با گرفتن میانگین در هر خوشه میتوانیم مراکز خوشه و به دنبال آن خوشههای جدید ایجاد کنیم. (با تکرار مراحل قبل) از جمله مشکلات این روش این است که بهینگی آن وابسته به انتخاب اولیه مراکز بوده و بنابراین بهینه نیست. مشکلات دیگر آن تعیین تعداد خوشهها و صفر شدن خوشهها میباشد.
مجموعه دادههای گل iris یا مجموعه اطلاعات آریز فیشر یک مجموعه داده چند متغیره است که توسط متخصص بریتانیا و زیست شناس رونالد فیشر در مقاله 1936 خود استفاده شده است. استفاده از چندین اندازه گیری در مشکلات تاکسیونی به عنوان مثال از تجزیه و تحلیل خطی خطی . گاهی اوقات داده های آیرس اندرسون نامیده می شود ، زیرا ادگار اندرسون داده ها را برای اندازه گیری تغییرات مورفولوژیکی گل های گل آفتاب سه گونه مرتبط جمع آوری کرده است. دو تن از این سه گونه در شبه جزیره گازپسی “همه از همان مرتع و در همان روز جمع شده بودند و در همان زمان توسط همان فرد با همان دستگاه اندازه گیری شد”.
مجموعه داده ها شامل 50 نمونه از هر یک از سه گونه Iris ( Iris setosa ، Iris virginica و Iris versicolor ) می باشد. چهار ویژگی از هر نمونه اندازه گیری شد: طول و عرض قاشق و گلبرگ ، در سانتی متر. بر اساس ترکیبی از این چهار ویژگی، فیشر یک مدل تبعیضی خطی برای تشخیص گونه ها از یکدیگر ایجاد کرد.
شبیه سازی خوشه بندی داده های IRIS و PIMA توسط الگوریتم K-means با متلب
شبیه سازی خوشه بندی داده های IRIS و PIMA توسط الگوریتم K-means با متلب توسط کارشناسان گروه ۱.۲.۳ پروژه پیاده سازی گردیده و به تعداد محدودی قابل فروش می باشد.فایلهای پروژه به صورت کامل پس از خرید فایل بلافاصله در اختیار شما قرار خواهد گرفت.
سفارش پروژه مشابه
درصورتیکه این پروژه دقیقا مطابق خواسته شما نمی باشد، با کلیک بر روی کلید زیر پروژه دلخواه خود را سفارش دهید.





دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.