توضیحات
شبیه سازی آموزشی مقاله تشخیص رقم دست نویس با استفاده از شبکه عصبی کانولوشن با پایتون
چکیده مقاله:
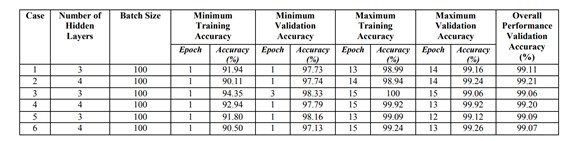
در چند وقت اخیر ، با افزایش شبکه عصبی مصنوعیANN) ) ، یادگیری عمیق با هوشمند سازی گسترده تر، در زمینه یادگیری ماشین پیچ و تاب چشمگیری ایجاد کرده است. یادگیری عمیق به دلیل کاربردهای متنوعی مانند نظارت ، بهداشت ، پزشکی ، ورزش ، رباتیک ، هواپیماهای بدون سرنشین و غیره به طور چشمگیری در زمینه های گسترده ای مورد استفاده قرار می گیرد. در یادگیری عمیق ، شبکه عصبی پیچشی (CNN) درمیان پشرفت ها دیدنی است که شبکه عصبی مصنوعیANN)) و استراتژی های به روز یادگیری عمیق را مخلوط می کند. این به طور گسترده ای در تشخیص الگو، طبقه بندی جملات، تشخیص گفتار، تشخیص چهره، طبقه بندی متن، تجزیه و تحلیل سند، شناسایی اعداد دست نویس استفاده شده است. هدف این مقاله مشاهده تنوع دقت CNN برای طبقه بندی اعداد دست نویس با استفاده از تعداد مختلف لایه های پنهان و دوره ها و مقایسه بین دقت در این موارد می-باشد. برای ارزیابی عملکرد CNN، ما آزمایش خود را با استفاده از مجموعه داده MNIST)) انجام دادیم. علاوه بر این ، شبکه با استفاده از نزول گرادیان تصادفی و الگوریتم backpropagation آموزش داده می شود.
مقدمه
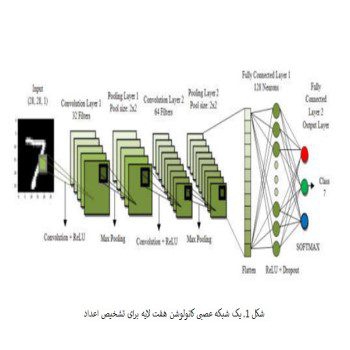
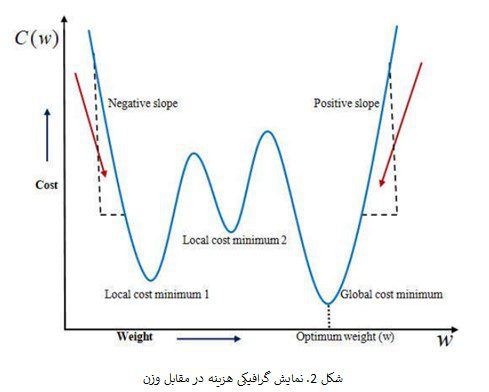
با گذشت زمان ، تعداد زمینه هایی که می توان در آنها از یادگیری عمیق استفاده کرد ، رو به افزایش است. از شبکه عصبی پیچشی ((CNN برای تجزیه و تحلیل تصاویر بصری استفاده میشود. تشخیص اشیا، تشخیص چهره ، رباتیک، تجزیه و تحلیل ویدئو، تقسیم بندی، تشخیص الگو، پردازش زبان طبیعی، شناسایی هرزنامه، طبقه بندی موضوع، تحلیل رگرسیون، تشخیص گفتار، طبقه بندی تصویر برخی از نمونه هایی است که می توان با استفاده از شبکه عصبی پیچشی ((CNN انجام داد. مدل بیولوژیکی سیستم های بصری پستانداران مدلی است که با استفاده از آن معماری شبکه عصبی پیچشی ((CNN الهام گرفته شده است. سلولهای قشر بینایی گربه به ناحیه کوچکی از محیط شناسایی شده که به عنوان میدان پذیرایی شناخته می شود ، حساس می شوند. این توسط D. H. Hubel و همکاران در سال 1062 یافت شد. مدل تشخیص الگو با الهام از کار D. H. Hubel و همکاران بدست آمده است. اولین بینایی ماشین در سال 1980 توسط فوكوشیما معرفی شد. در سال 1998 ، چارچوب CNN توسط LeCun و همكاران طراحی شد که دارای هفت لایه شبکه عصبی پیچشی (CNN) بود. این شبکه در طبقه بندی اعداد دست نویس به صورت مستقیم از مقادیر پیکسل تصاویر، ماهر بود. از گرادیان کاهشی و الگوریتم backpropagation برا ی آموزش مدل استفاده شده است. به عوان ورودی تصاویر اعداد دست نویس به مدل داده میشود. یک شبکه عصبی مصنوعیANN) ) ساده دارای یک لایه ورودی و یک لایه خروجی و تعدادی لایه مخفی بین این دو میباشد. (برای اختصار زین پس شبکه عصبی مصنوعی را ANN و شبکه عصبی پیچشی CNN مینامیم). معماری مدل CNN بسیار شبیه به مدل ANN میباشد. چندین نورون در هر لایه مدل ANN وجود دارد. جمع تمام وزن های نورون های لایه قبلی به علاوه یک مقدار biased ه عنوان ورودی به لایه بعدی داده میشوند. در مدل CNN لایه ها داری سه بعد میباشند. در این مدل تمامی نورونها به صورت کامل به یکدیگر متصل نیستند. در عوض هر نورون به یک میدان داخلی متصل میباشد. برای آموزش شبکه ، یک تابع هزینه ایجاد می شود. خروجی شبکه را با خروجی مورد نظر مقایسه می کند. سیگنال ها یه صورتی تکراری به سیستم باز می گردد. برای به حداقل رساندن مقدار تابع هزینه که عملکرد شبکه را افزایش می دهد، وزنها و biases مشترک را در همه لایه ها به روز کنید. هدف این مقاله مشاهده تاثیر لایه های مخفی مدل CNN بر روی تصاویر اعداد دستنویس میباشد. با استفاده از Tensorflow که یک کتابخانه شبکه عصبی در ئایتون میباشد، انواع مختلفی از مدل CNN را بر روی داده های MNIST اعمال کردیم. هدف اصلی این مقاله تجزیه و تحلیل تغییرات نتایج برای استفاده از ترکیبی متفاوت از لایه های پنهان CNN است. الگوریتم گرادیان تصادفی و الگوریتم backpropagation برای آموزش شبکه و الگوریتم feedforward برای آزمایش استفاده می شود.
پایگاه داده MNIST
MNIST مجموعه بزرگی از مجموعه داده های رایانه ای است که به طور گسترده ای برای آموزش و آزمایش سیستم های مختلف استفاده می شود. این پایگاه داده از دو مجموعه داده ویژه موسسه ملی استاندارد و فناوری (NIST) ایجاد شده است که تصاویر دودویی از اعداد دست نویس را در خود جای داده است. مجموعه آموزش شامل اعداد دست نویس از 250 نفر است ، که شامل 50٪ مجموعه داده های آموزشی را کارکنان اداره سرشماری و بقیه آن مربوط به دانش آموزان دبیرستان است. با این حال ، اغلب به عنوان اولین مجموعه داده در میان مجموعه های داده دیگر برای اثبات اثربخشی شبکه های عصبی نسبت داده می شود.

این پایگاه داده شامل 60،000 تصویر مورد استفاده برای آموزش است و همچنین تعداد کمی از آنها برای اعتبارسنجی متقابل و 10،000 مورد از اینها برای آزمایش نیز مورد استفاده قرار می گیرند. تمام اعداد در مقیاس خاکستری هستند و در یک اندازه ثابت قرار می گیرندکه سایز هر تصویر 28 * 28 است. از آنجا که همه تصاویر 28 × 28 پیکسل هستند ، آرایه ای را تشکیل می دهیم که می تواند به صورت بردار یک بعدی 28 * 28 = 784 مسطح شود.
شبیه سازی آموزشی مقاله تشخیص رقم دست نویس با استفاده از شبکه عصبی کانولوشن با پایتون توسط کارشناسان گروه ۱.۲.۳ پروژه پیاده سازی گردیده و به تعداد محدودی قابل فروش می باشد.
- فایلهای پروژه به صورت کامل پس از خرید فایل بلافاصله در اختیار شما قرار خواهد گرفت.







دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.